
Decathlon, a renowned sporting goods retailer, offers various sports apparel, footwear, and equipment. This article explores how to scrape apparel data by category using Playwright and Python to collect valuable insights into product trends and pricing from Decathlon's website.
Playwright is a library that helps control web browsers like Chromium, Firefox, and WebKit using programming languages such as Python and JavaScript. It's an excellent tool for data scraping from ecommerce website and automating tasks like form submissions and button clicks. Utilizing Playwright, we will navigate through each category and gather essential product information, including name, price, and description.
This tutorial provides a foundational understanding of using Playwright and Python for scraping Decathlon's website, focusing on extracting key data attributes from individual product pages.
List of Data Fields
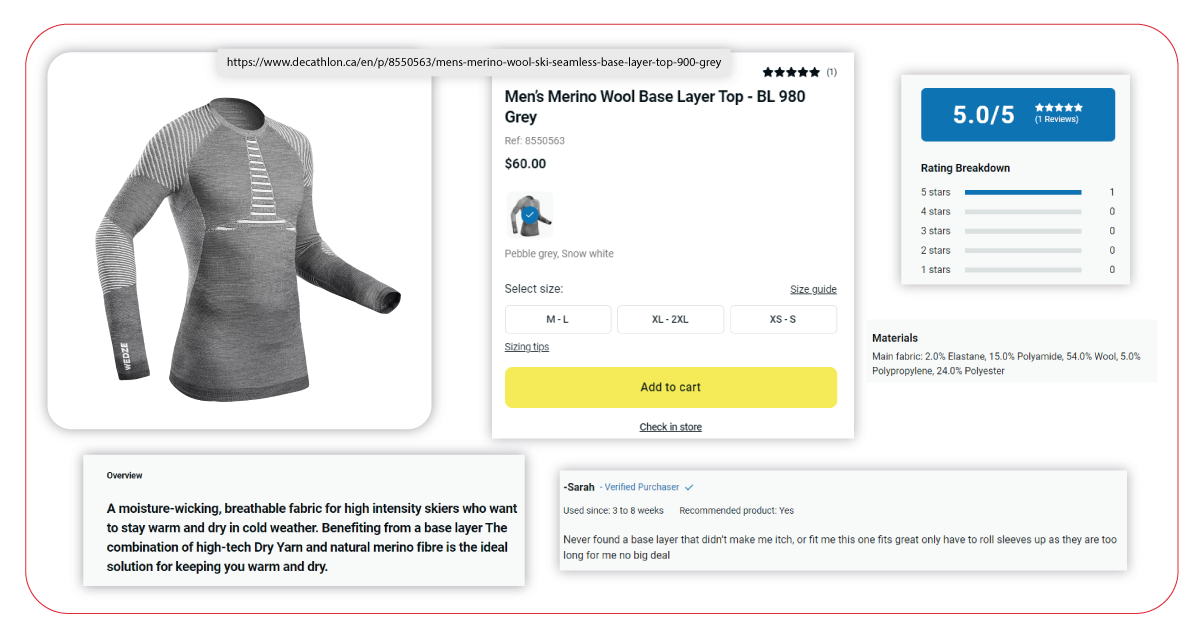
- Product URL
- Product Name
- Brand
- MRP
- Sale Price
- Number of Reviews
- Ratings
- Color
- Features
- Product Information
Below, you'll find a step-by-step guide to scrape Decathlon with Playwright in Python.
Import Necessary Libraries
To initiate the procedure, we should begin by importing the necessary libraries to enable us to interact with the website and retrieve the essential information.

The following libraries serve specific purposes in automating browser testing with Playwright:
'random': This library is employed to generate random numbers, which can help create test data or shuffle the order of tests.
'asyncio': It is used for managing asynchronous programming in Python, particularly when utilizing Playwright's asynchronous API.
'pandas': This library is helpful for data analysis and manipulation. In this tutorial, it is applicable to store and manipulate data acquired from the web pages under examination.
'async_playwright': This library represents the asynchronous API for Playwright, and it plays a crucial role in automating browser testing. The asynchronous nature of this API enables the execution of multiple operations concurrently, resulting in faster and more efficient testing procedures.
These libraries collectively support the automation of browser testing with Playwright, covering tasks such as generating test data, managing asynchronous operations, data handling, and automating interactions with web browsers.
Scrape Product URLs
The next step involves extracting the URLs of the apparel products based on their respective categories.

In this context, our Decathlon product data scraping services use the function 'get_product_urls' to retrieve product URLs from a web page. This function harnesses the capabilities of the Playwright library for automating browser testing and gathering the resulting product URLs from the webpage. It accepts two parameters: 'browser' and 'page,' both instances of the Playwright Browser and Page classes, respectively.
The process begins by using 'page.querySelectorAll()' to locate all elements on the page containing the product URLs. Subsequently, a for loop helps to iterate through these elements, extracting the 'href' attribute, which contains the product page's URL.
Additionally, the function checks for a "next" button on the page. If such a button exists, the function clicks on it and invokes itself recursively to retrieve URLs from the subsequent page. This recursive process continues until all relevant product URLs are available.
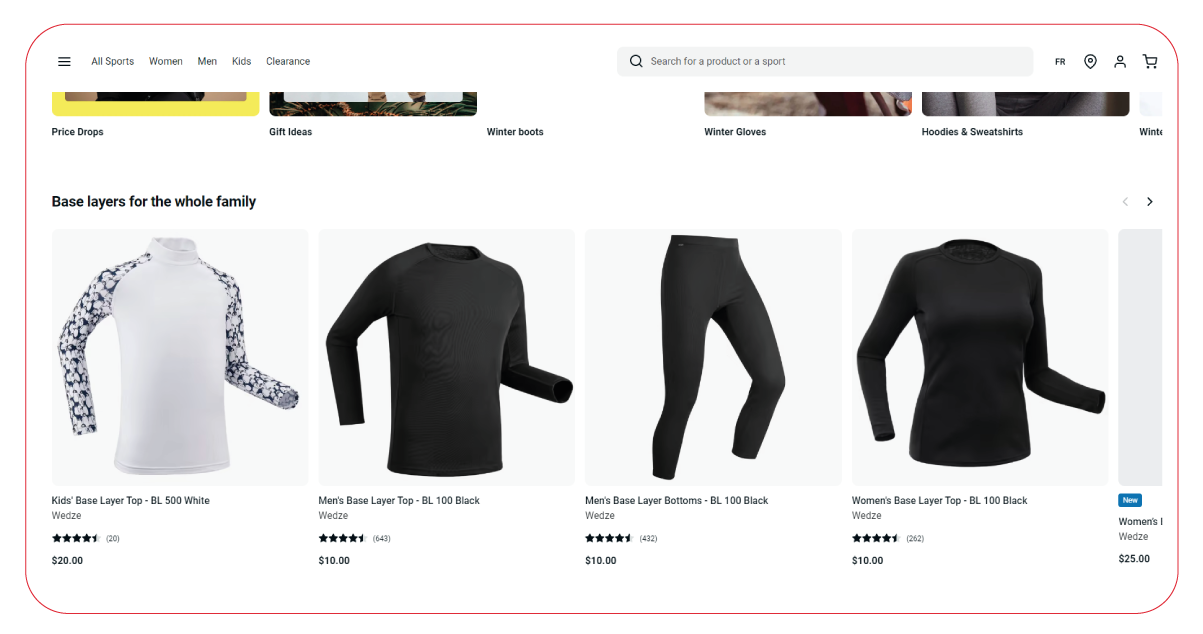
In this scenario, we aim to scrape product URLs categorized by product type. To achieve this, we follow a two-step process. Initially, we click the product category button to reveal the list of available categories. Subsequently, we click on each category to filter and gather the relevant product URLs.

In this context, we utilize the Python function 'filter_products' to filter products on the Decathlon website by their respective categories and furnish a list of product URLs, along with their associated categories.
The process commences with the expansion of the product category section on the website, followed by the activation of the "Show All" button to reveal all available subcategories. Subsequently, a predefined list of subcategories is available, and the function iterates through each. For each subcategory, the corresponding checkbox applies the desired filtering criteria to the products. After selecting a subcategory, the function patiently waits for the page to load and employs the 'get_product_urls' function to extract the list of product URLs.
After processing all the subcategories, the function performs a cleanup operation by clicking the "Clear" button for each subcategory, effectively resetting the filters.
Scrape Product Name
The subsequent step involves extracting the names of the products from the web pages.

In this context, we've employed an asynchronous function called 'get_product_name,' which accepts a 'page' argument representing a Playwright page object. Within this function, locate the product name element on the page using the 'query_selector()' method of the 'page' object, with the appropriate CSS selector provided. On locating the element, the function retrieves the text content of the element and returns it as a string.
However, in the event of an exception occurring during the process, such as when the element is not available on the page, the function assigns the 'product_name' variable the value "Not Available."
Scrape Product Brand
The subsequent step involves extracting the brand information of the products from the web pages.

Much like extracting the product name, the function 'get_brand_name' is responsible for retrieving the brand name of a product from a web page. The process involves an attempt to locate the brand name element using a CSS selector that targets the specific element containing the brand name. When the element is successfully available, the function extracts the text content using the 'text_content()' method and assigns it to the 'brand_name' variable. It's important that the brand name may include both the primary brand name and any sub-brand names, for instance, "Decathlon Wedze," where "Wedze" is one of the sub-brands of Decathlon. If an exception occurs during the search or extraction process for the brand name element, the function defaults to assigning "Not Available" to the brand name.
A similar approach can extract other attributes, such as MRP, sale price, number of reviews, ratings, color, features, and product information. For each attribute, a separate function is available, utilizing the 'query_selector' method and 'text_content' or equivalent methods to pinpoint the relevant element on the page and gather the desired information. Additionally, it's essential to adjust the CSS selectors used within these functions to align with the specific structure of the scraped web page.
Scrape MRP of Products

Scrape Sales Price

Scrape Number of Reviews

Scrape Ratings

Scrape Features of Products
![]()
Scrape Product Information

The code defines an asynchronous function named get_ProductInformation, which takes a page object as its argument. This function can retrieve product information from Decathlon's website. It iterates through each entry in the product information and extracts the text content from the "name" and "value" elements using the text_content method. Subsequently, it eliminates any newline characters from the collected strings with the replace method and stores the name-value pair in a dictionary named product information. If an exception is raised, for instance, if the element is unavailable or unable to extract, the code assigns the "Not Available" value to the ProductInformation dictionary.
Implementing Maximum Retry Limit for Request Retries
In web scraping, request retries are critical in handling temporary network errors or unexpected responses from websites. The primary goal is to reattempt a failed request, increasing the likelihood of a successful outcome.
Before accessing the target URL, the script incorporates a retry mechanism to address potential timeouts. It employs a while loop to repeatedly attempt the URL navigation until the request succeeds or the maximum number of retries has been exhausted. On achieving the maximum retry limit without success, the script raises an exception.
This code represents a function that executes a request to a specified link and handles retries in case of failure. This function proves valuable when scraping web pages, as network issues or timeouts can occasionally lead to request failures.

This function is responsible for requesting a specific URL using the 'goto' method provided by the Playwright library's page object. In the event of a request failure, the function attempts to retry it, allowing for a maximum of five retries as determined by the constant MAX_RETRIES. The function incorporates the 'asyncio.sleep' method ranging from 1 to 5 seconds between each retry to avoid immediate reattempts. This deliberate pause is essential to prevent overloading the request and potentially causing more failures.
The perform_request_with_retry function expects two arguments: 'page' and 'link.' The 'page' argument represents the Playwright page object responsible for the request, while the 'link' argument specifies the URL to the directed request. Continuing with the process, we invoke the functions and store the extracted data in an initially empty list.

This Python script employs an asynchronous function called "main" to scrape product information from Decathlon web pages. It utilizes the Playwright library to initiate a Firefox browser, navigate to the Decathlon page, and extract the URLs of each product using the "extract_product_urls" function. Store these URLs in a list named "product_url." The script then iterates through each product URL, loads the product page using the "perform_request_with_retry" function, and retrieves various details such as the product name, brand, star rating, number of reviews, MRP, sale price, number of reviews, ratings, color, features, and product information.
Store the information as tuples in a list called "data." Additionally, the script displays a progress message after processing every 10 product URLs and a completion message once all the product URLs have been processed. The data in the "data" list is then converted into a Pandas DataFrame and saved as a CSV file using the "to_csv" method. Finally, the browser is closed using the "browser.close()" statement. Execute the script by calling the "main" function using the "asyncio.run(main())" statement, running it as an asynchronous coroutine.
Conclusion: In today's rapidly evolving business landscape, data is paramount, and web scraping is the gateway to unlocking its full potential. With the correct data and tools, brands can gain profound insights into the market, facilitating informed decisions that drive growth and profitability.
To remain competitive in the modern business world, brands must leverage every advantage available to stay ahead of competitors. It is where web scraping becomes crucial, enabling companies to access vital insights on market trends, pricing strategies, and competitor data.
By harnessing the capabilities of Playwright and Python tools, companies can extract valuable data from websites like Decathlon, obtaining a wealth of information about product offerings, pricing, and other critical metrics. When combined with the ecommerce website data collection services of a leading web scraping company, the results can be truly transformative and game-changing.
At Product Data Scrape, we uphold unwavering ethical standards in every facet of our operations, be it our Competitor Price Monitoring Services or Mobile App Data Scraping. With a worldwide footprint encompassing numerous offices, we steadfastly provide outstanding and transparent services to cater to the varied requirements of our esteemed clientele.



































.webp)





