
Introduction to Web Scraping with Node.js
Web scraping in Node.js is a popular choice due to its non-blocking, event-driven architecture, which makes it an efficient platform for data extraction. With Node.js, you can easily interact with web pages, send HTTP requests, and parse HTML content to extract the information you need. This guide will walk you through how to use Node.js to scrape product data, such as prices, stock levels, descriptions, and other eCommerce details, from various websites using Product Data Scrape.
Setting Up the Environment
Installing Node.js

To begin scraping with Node.js, first, you need to have Node.js installed. Here’s how you can install it:
1. Visit Node.js official website.
2. Download the latest LTS version for your operating system.
3. Follow the installation instructions for your platform.
4. Verify the installation by running the following commands in your terminal:
node -v
npm -v
Installing Dependencies

Once Node.js is installed, you will need a few libraries to help with the scraping process. These include:
- Axios: To make HTTP requests.
- Cheerio: A fast, flexible, and lean implementation of jQuery to parse HTML.
- Product Data Scrape: (A fictional library, assuming you're scraping product data specifically).
Install the necessary libraries:
npm init -y
npm install axios cheerio productdata-scrape
Understanding Product Data Scrape

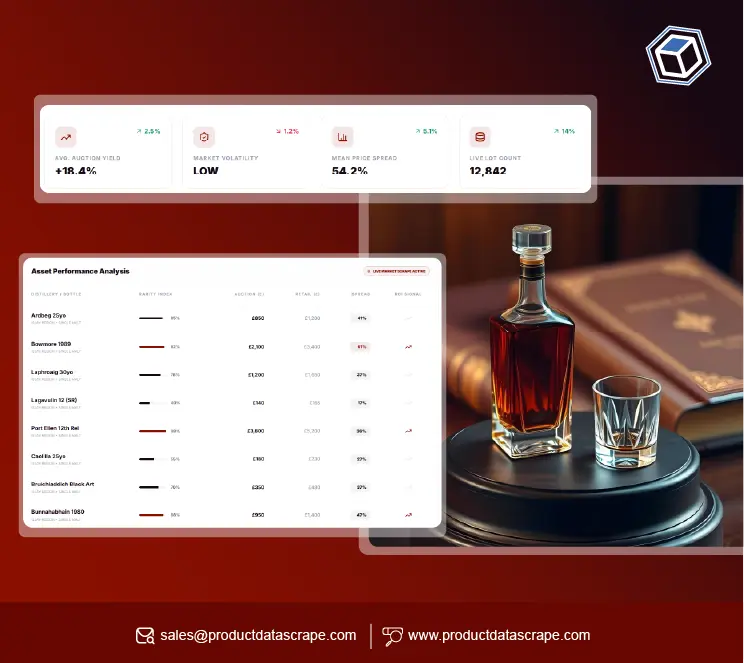
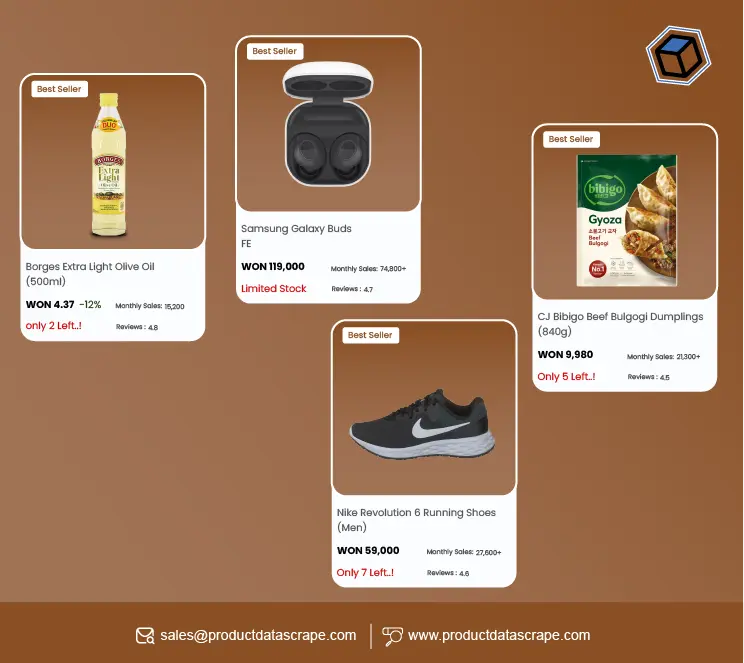
Product Data Scrape is a robust framework designed to help scrape product-related data from eCommerce platforms. Some key features include:
- Ability to extract prices, product descriptions, stock levels, and reviews.
- Support for scraping multiple pages for large catalogs of products.
- Integration with popular eCommerce sites like Amazon, eBay, and Walmart.
- Handling of anti-scraping technologies like CAPTCHA and JavaScript rendering.
How Product Data Scrape Works
Product Data Scrape works by sending HTTP requests to a website’s server and then parsing the HTML to extract structured data. For example, if you're scraping a product listing page, Product Data Scrape will:
1. Load the page HTML.
2. Use selectors (similar to jQuery) to extract relevant data points.
3. Parse the data and return it in a structured format like JSON.
Basic Web Scraping in Node.js
Let’s start with a simple example of scraping product data using Axios and Cheerio.
Example: Scraping Product Data
Suppose we want to scrape the price, title, and description of a product from an eCommerce site.
In this example:
axios.get(url) fetches the HTML content of the product page.cheerio.load(data) loads the HTML into Cheerio for parsing.$('selector') uses jQuery-like syntax to find and extract specific elements.
Advanced Techniques in Scraping
Handling Dynamic Content (JavaScript Rendering)
Many modern websites load content dynamically using JavaScript, meaning that the data may not be present in the initial HTML. To scrape such sites, we can use headless browsers like Puppeteer or Playwright that can render JavaScript content.
Example using Puppeteer:
This allows you to scrape websites with dynamic content that might not be available in the raw HTML.
Best Practices for Web Scraping
Handling Errors and Timeouts
Web scraping can encounter various issues such as timeouts, missing data, or incorrect responses. Handle these gracefully with error-catching mechanisms in your code.
Avoiding IP Blocks and Rate Limiting
Websites may block your IP address if they detect high-frequency requests. To avoid this:
- Use rotating proxies or VPNs.
- Respect
robots.txt to ensure you're not scraping prohibited content.
- Introduce delays between requests using
setTimeout or libraries like Puppeteer-cluster.
Data Storage and Processing
Storing Data in Databases
Once you’ve scraped the data, you may want to store it in a database for future use. You can use databases like MongoDB or MySQL. Here’s how to store scraped product data in MongoDB:
Exporting Data to CSV/JSON
If you prefer to export your scraped data to a file, here’s how to write the data to a JSON file:
Legal and Ethical Considerations
While web scraping is powerful, it’s important to follow ethical and legal guidelines:
- Always check the website’s robots.txt file for scraping rules.
- Avoid scraping personal or sensitive information.
- Comply with the Terms of Service of the websites you scrape.
Scaling Your Scraping Operations
Distributed Scraping with Node.js
When scraping large amounts of data, it's essential to distribute the load across multiple servers to avoid getting blocked. You can use tools like Docker for containerization and Kubernetes for orchestration.
Using Headless Browsers
For websites that require interaction (e.g., clicking buttons or filling out forms), using headless browsers like Puppeteer or Playwright allows for advanced interaction and data scraping.
Conclusion
In 2025, web scraping with Node.js continues to be a highly effective method for automating the collection of data from the web. With the use of tools like Product Data Scrape, Axios, Cheerio, and headless browsers like Puppeteer, you can scale your scraping operations, handle dynamic content, and ensure your data is accurate and well-structured.





































.webp)












