
Introduction
Web scraping is the process of extracting data from websites, but scraping JavaScript-heavy
websites data scraping presents unique challenges. Websites relying heavily on JavaScript for
rendering content can make it difficult to scrape data using traditional web scraping methods,
such as simple HTTP requests. These websites typically use JavaScript frameworks, like React,
Angular, or Vue.js, to render dynamic content on the client side, meaning the content is not
readily available in the static HTML. To scrape these websites effectively, specialized scraping
techniques and tools are required.
This article will explore the best web scraping methods for JavaScript-heavy websites, with
practical examples from e-commerce and retail websites that employ dynamic content loading.
Using the right tools and techniques, you can extract valuable data from such websites for
competitive analysis, market research, and business insights.
Understanding JavaScript-Heavy Websites
JavaScript-heavy websites use JavaScript to load content after the page is loaded dynamically. This is common in single-page applications (SPAs), where content is fetched and updated without refreshing the entire page. For example, when browsing platforms like Amazon or eBay, new product listings are dynamically added as you scroll down the page. These sites fetch product data via JavaScript, and this content is often not part of the initial page HTML sent by the server.
Unlike static HTML pages, where content is directly available in the markup, JavaScript-heavy websites load data asynchronously using technologies like AJAX or fetch API. This content is rendered on the browser using JavaScript and may not appear in the page's raw HTML or HTTP response. As a result, traditional e-commerce website scraping methods—using HTTP requests to get HTML—fail to capture this dynamic content.
Challenges of Scraping JavaScript-Heavy Websites
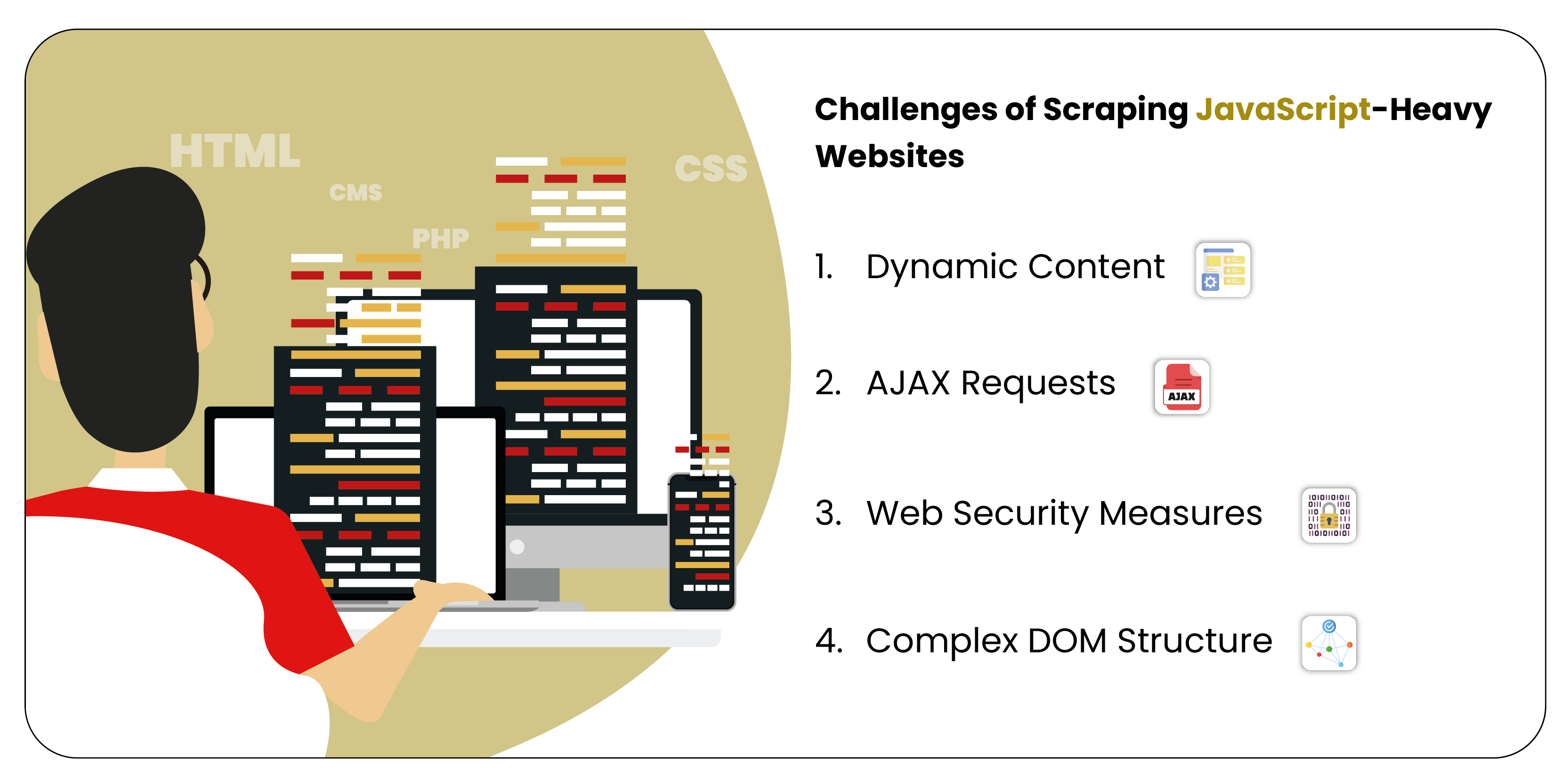
present unique challenges due to dynamic content loading, complex
DOM structures, and anti-bot security measures. Traditional scraping methods often fail to
capture data, requiring advanced techniques and specialized tools for effective extraction.
Dynamic Content: The primary challenge with JavaScript-heavy websites is that the content is rendered dynamically using JavaScript after the page loads. Web scraping services that rely on parsing static HTML will miss this dynamically loaded content.
AJAX Requests: Many websites use AJAX to load data in the background without reloading the page. Identifying and mimicking these AJAX requests can be challenging, as they may not be immediately visible in the page's source code. This is where scraping heavy websites requires advanced techniques.
Web Security Measures: Websites that use JavaScript often employ various anti-bot measures, such as CAPTCHA, rate limiting, and dynamic content obfuscation. These measures are designed to detect and block scraping bots, which pose a challenge for Javascript data scraping services.
Complex DOM Structure: JavaScript-heavy websites often have complex Document Object Models (DOM), making extracting meaningful data harder, especially when content is nested deep within dynamically generated elements.
Best Web Scraping Methods for JavaScript-Heavy Websites
There are several methods and tools available to scrape data from JavaScript-heavy websites.
Each has strengths and weaknesses, so selecting the right one depends on the website you're
scraping and the data you need.
Using Headless Browsers (e.g., Puppeteer, Playwright)
-01.webp)
Headless browsers allow you to render JavaScript just like a regular browser but without the
graphical interface. They load the entire webpage, including dynamic content rendered by
JavaScript, allowing you to extract data from the page.
Puppeteer is a popular headless browser automation tool for Node.js. It controls a Chrome
browser and allows you to interact with the page, trigger JavaScript, and scrape data. With
Puppeteer, you can emulate user interactions like clicking buttons, filling out forms, and
scrolling through pages. This makes it particularly useful for scraping websites that load content
dynamically based on user actions, such as infinite scrolling on e-commerce websites.
Example: eCommerce dataset scraping from an e-commerce website like Amazon using Puppeteer.
Puppeteer allows you to interact with the page, load JavaScript content, and extract structured
data. This method is highly effective for scraping e-commerce websites like Walmart and eBay,
where content is dynamically loaded based on user interaction.
Another great tool in this category is Playwright. Similar to Puppeteer, it supports more
browsers (Chromium, Firefox, WebKit) and provides additional features for modern web
scraping tasks.
Simulating AJAX Requests

Many JavaScript-heavy websites fetch data asynchronously using AJAX requests. By inspecting
the network activity in the browser's developer tools, you can often identify the API endpoints
used to fetch data. Once you know these endpoints, you can bypass the JavaScript rendering
and scrape the data directly from the API.
For example, e-commerce websites like Best Buy or Target often use AJAX to load product
listings as you scroll through the page. Instead of scraping the website's HTML, you can directly
scrape the AJAX API that returns the product data in a structured format (usually JSON or XML).
Simulating AJAX requests is an efficient way to scrape data from JavaScript-heavy websites,
bypassing the need to render the page and interact with JavaScript. However, this method
requires a solid understanding of the website's underlying API structure.
Using Browser Automation Tools (e.g., Selenium)
Selenium is another popular tool for automating browsers. It allows you to control a real
browser (e.g., Chrome, Firefox) and interact with a website just like a human user would.
Selenium is an excellent option for scraping complex websites that require interactions, such as
clicking buttons or filling out forms.
Selenium can be used with other tools like BeautifulSoup to extract data after the page has fully
loaded. While Selenium is slower than headless browsers like Puppeteer, it's still a powerful
tool for scraping websites that require complex interaction or JavaScript rendering.
Using Scrapy with Splash

Scrapy is a robust web scraping framework for Python that allows you to extract data from
websites. To scrape JavaScript-heavy websites, you can use Splash, an open-source headless
browser designed for web scraping. Splash can render JavaScript, execute AJAX requests, and
capture screenshots of dynamic content, making it an excellent option for scraping data from
websites that rely heavily on JavaScript.
Scrapy and Splash work well together. Scrapy handles the scheduling and downloading of web
pages, while Splash renders JavaScript-heavy pages and extracts the content.
Scrapy and Splash allow you to scrape dynamic websites with complex JavaScript rendering by
combining efficient crawling and rendering features.
Example Websites for Scraping JavaScript Content
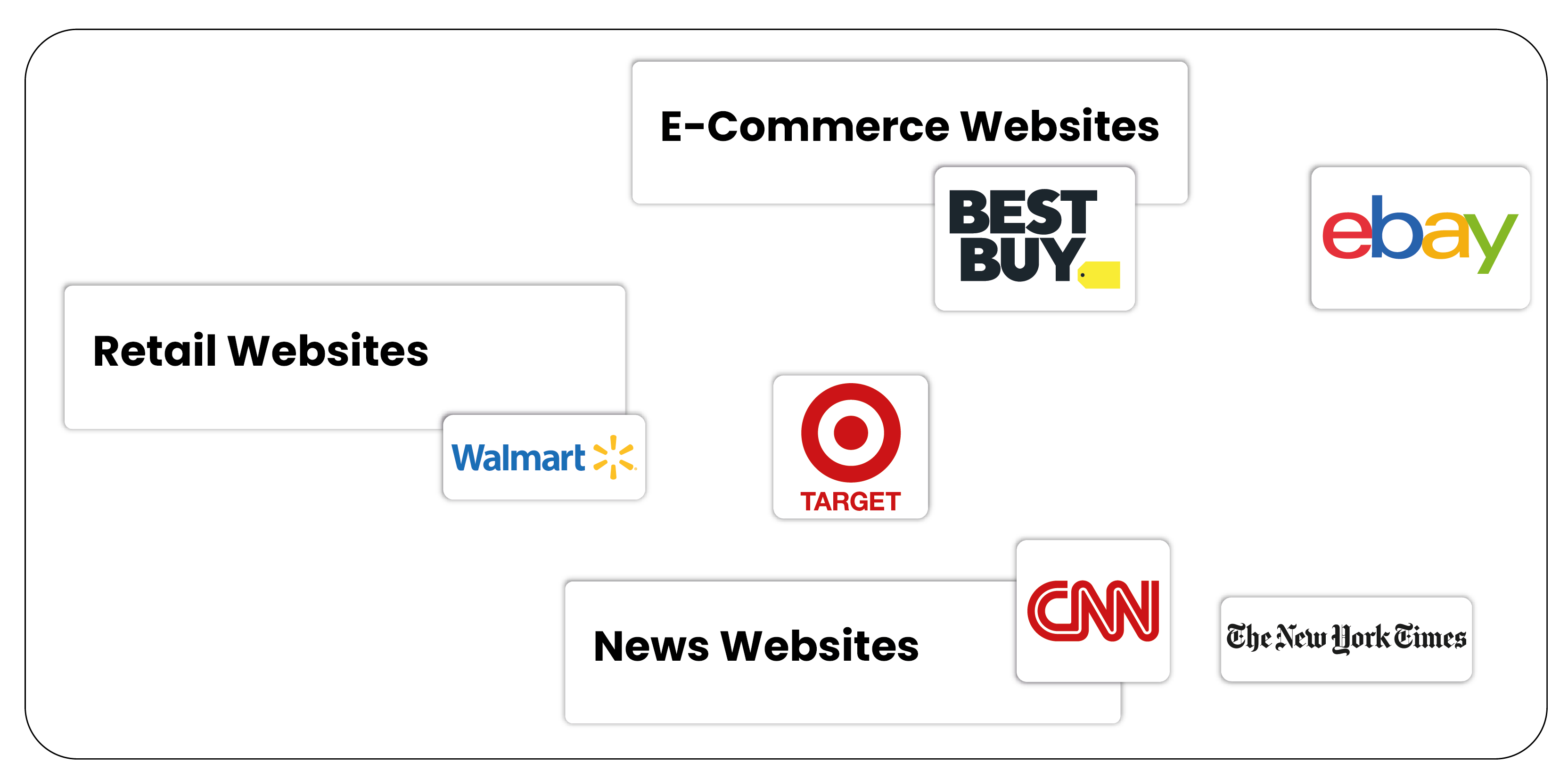
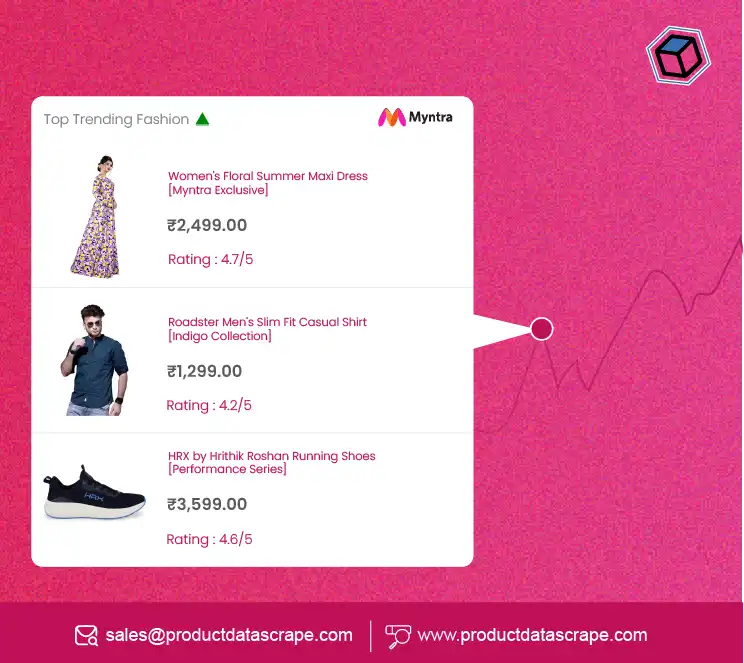
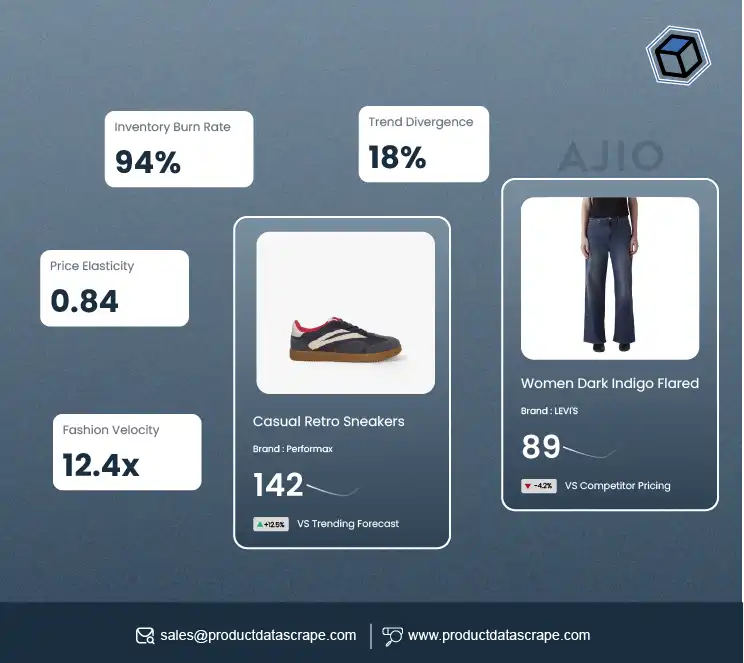
- E-Commerce Websites: Platforms like Amazon, eBay, Walmart, and Best Buy heavily rely on JavaScript to dynamically load product listings, prices, availability, and customer reviews. This dynamic nature requires advanced scraping techniques, such as using headless browsers or simulating AJAX requests to capture up-to-date product data. For example, web scraping Best Buy e-commerce product data enables businesses to gather real-time pricing and availability information, helping them stay competitive in the marketplace. Similarly, web scraping eBay e-commerce product data allows businesses to extract product listings, pricing details, and auction results for thorough market analysis.
- Retail Websites: Retailers like Target and Macy's also use JavaScript to display real-time product data, including stock availability, pricing, and promotional offers. Web scraping these sites allows businesses to monitor competitors, identify trends, and optimize pricing strategies. For instance, web scraping Walmart e-commerce product data offers crucial insights into product pricing, availability, customer reviews, and promotions, enabling businesses to adjust their offerings effectively. Likewise, web scraping Target e-commerce product data provides valuable data for tracking product trends and understanding retail pricing strategies, while web scraping Macy's e-commerce product data helps monitor stock and identify market shifts.
- News Websites: Leading news platforms like CNN and The New York Times utilize JavaScript to load articles, images, videos, and advertisements dynamically. Scraping these sites allows businesses to extract key article data and analyze content trends across various media outlets. With this information, companies can gauge public sentiment, track trending topics, and tailor their marketing strategies accordingly.
Conclusion
Scraping JavaScript-heavy websites requires more than just basic HTML parsing. By using specialized tools such as Puppeteer, Selenium, Scrapy with Splash, and Playwright, businesses can overcome the challenges posed by dynamic content loading. These tools enable the extraction of valuable data from e-commerce platforms, retail websites, and other JavaScript-intensive sites, helping businesses gather competitive intelligence, track market trends, and enhance their data analysis efforts.
With the ability to access real-time information, businesses can refine their Pricing Strategy and stay ahead of competitors by monitoring pricing fluctuations. Price Monitoring using these advanced tools helps retailers make timely adjustments to their prices, improving profitability and ensuring they stay competitive in fast-paced markets.
Choosing the best scraping method depends on the website's complexity, needed data, and available resources. With the right approach, scraping JavaScript-heavy websites becomes a powerful tool for unlocking valuable insights hidden in dynamic content.
At Product Data Scrape, we strongly emphasize ethical practices across all our services, including Competitor Price Monitoring and Mobile App Data Scraping. Our commitment to transparency and integrity is at the heart of everything we do. With a global presence and a focus on personalized solutions, we aim to exceed client expectations and drive success in data analytics. Our dedication to ethical principles ensures that our operations are both responsible and effective.



































.webp)





