
Introduction
- Overview of Web Scraping: The importance of web scraping in data collection, particularly in extracting product data from e-commerce sites.
- Role of Data Pipelines: How data pipelines streamline the collection, processing, and utilization of scraped data.
- Purpose of the Guide: Explain how web scraping fits within a data pipeline for efficient product data extraction, and its use cases in various industries.
What is Web Scraping?

- Definition and Key Concepts: Understanding web scraping, including the basics of crawling, scraping, and parsing data.
- Types of Data Scraping: Focus on product data scraping from e-commerce sites (e.g., product names, prices, reviews, availability).
- Legal and Ethical Considerations: A brief mention of best practices, terms of use, and compliance issues like GDPR.
Understanding Data Pipelines

- Definition of a Data Pipeline: An overview of a data pipeline and its components (data collection, cleaning, transformation, storage).
- Role of Data Pipelines in Web Scraping: How data pipelines help manage large-scale data extraction, automate processes, and provide scalable solutions.
- Pipeline vs. One-time Scraping: Benefits of a data pipeline over one-off scraping scripts in terms of automation, maintenance, and error handling.
Components of a Web Scraping Data Pipeline

Web Scraping Tools and Frameworks:
- Introduction to popular tools (e.g., Scrapy, BeautifulSoup, Selenium, Puppeteer).
- How these tools are used in scraping product data from e-commerce websites.
Data Collection Layer:
- How data is fetched from websites: HTTP requests, API scraping, and HTML parsing.
- Challenges in data extraction, such as CAPTCHAs, dynamic content, or anti-scraping measures.
Data Transformation Layer:
- Methods to clean and transform scraped data for consistency and accuracy (e.g., price normalization, format conversion).
- Example of transforming unstructured product data into structured formats (e.g., CSV, JSON).
Data Storage:
- Storing scraped product data in databases (e.g., SQL, NoSQL, cloud storage solutions).
- Choosing between relational databases and NoSQL for different use cases.
Automation and Scheduling:
- Automating the data pipeline using cron jobs, Airflow, or cloud services like AWS Lambda.
- Why automation is essential for keeping product data up to date.
Monitoring and Maintenance:
- Continuous monitoring of the data pipeline to ensure reliability.
- How to handle errors, retries, and broken links during the scraping process.
Product Data Scraping in E-Commerce

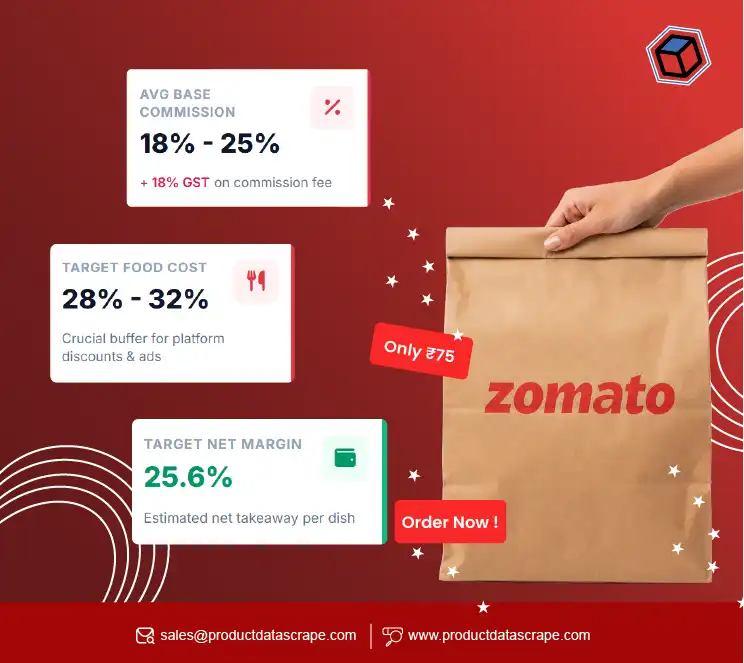
- Why Product Data Matters: Understanding the significance of scraping e-commerce sites for product information like pricing, stock availability, descriptions, and images.
- How to Scrape Product Data: Techniques for scraping product data efficiently from websites like Amazon, eBay, Walmart, and smaller e-commerce platforms.
- Challenges and Solutions:
- Handling dynamic content (JavaScript, AJAX).
- Anti-scraping technologies (CAPTCHAs, rate-limiting).
- Ethical considerations in scraping product data.
Case Studies of Web Scraping Data Pipelines
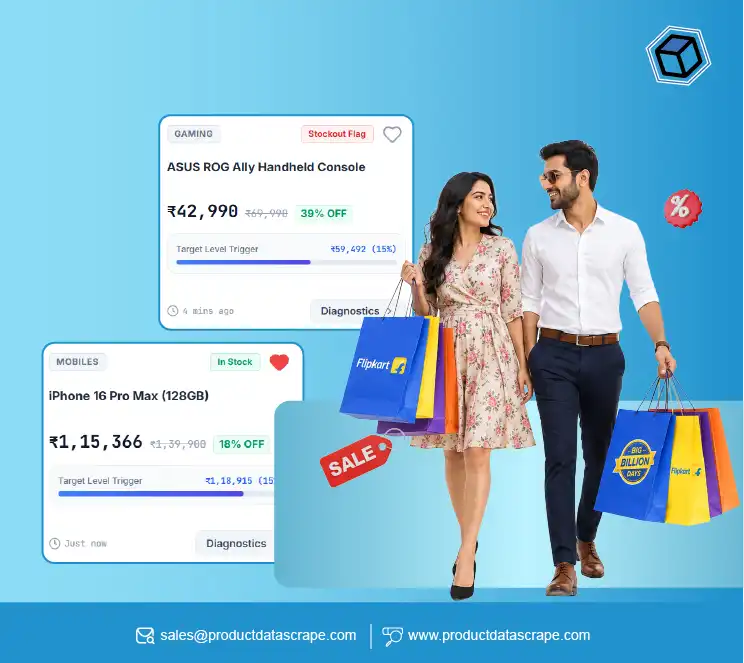
Case Study 1: E-Commerce Product Price Comparison:
- Using data pipelines to collect and compare product prices across different websites.
- Benefits for businesses in competitive pricing and market analysis.
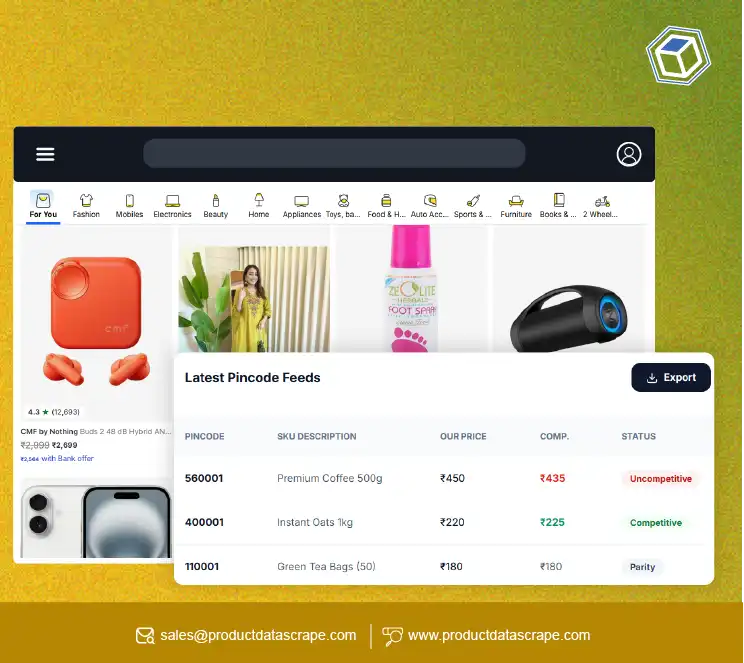
Case Study 2: Inventory and Stock Tracking:
- Example of using data pipelines to track stock levels, pricing changes, and availability over time.
- Use case for businesses in supply chain management and real-time market insights.
Advanced Techniques in Product Data Scraping

1. Handling JavaScript-heavy Websites:
- Using tools like Puppeteer or Selenium for scraping dynamic websites.
- How to deal with infinite scrolling and content loaded via AJAX.
2. Bypassing Anti-Scraping Mechanisms:
- IP rotation, proxies, and CAPTCHA solving tools.
- Rate-limiting and managing bot detection measures.
3. Integrating APIs for Data Collection:
- Scraping through public APIs when available.
- Comparing API scraping vs. traditional HTML scraping in terms of efficiency and reliability.
Best Practices and Tips for Web Scraping in Data Pipelines
- Error Handling and Debugging: How to deal with failed scraping attempts, missing data, and data quality issues.
- Optimizing Pipeline Performance: Techniques for improving scraping speed and data processing efficiency (e.g., parallel processing, multi-threading).
- Scalability Considerations: How to scale your scraping operations as data volume increases.
Conclusion
- Recap of Key Points: Summary of the importance of integrating web scraping into data pipelines, and how it can enhance product data analysis and decision-making.
- Future Trends: Predictions for the future of web scraping in 2025, including new technologies and evolving industry needs.
- Final Thoughts: The ongoing significance of web scraping in various industries, and why businesses should invest in efficient, scalable scraping data pipelines.



































.webp)





