
Introduction
Web scraping is a crucial technique for data extraction, enabling the collection of structured
and unstructured data from websites. The demand for efficient and accurate data gathering
grows as the internet expands. One of the most powerful tools in web scraping is RegEx
(regular expressions). Web Scraping Using RegEx allows developers to precisely match and
extract text patterns from web pages, making it an invaluable tool for extracting specific
information, such as product details, contact information, or pricing data. By leveraging RegEx
for data extraction service, developers can enhance the accuracy and efficiency of their
scraping tasks, even when dealing with complex or large datasets. This method provides
significant advantages, such as faster data retrieval and reduced dependencies on external
libraries. However, challenges like handling dynamic content and maintaining pattern flexibility
require careful consideration. This article explores the key benefits and potential hurdles when
using RegEx for web scraping.
Understanding Web Scraping and Regular Expressions
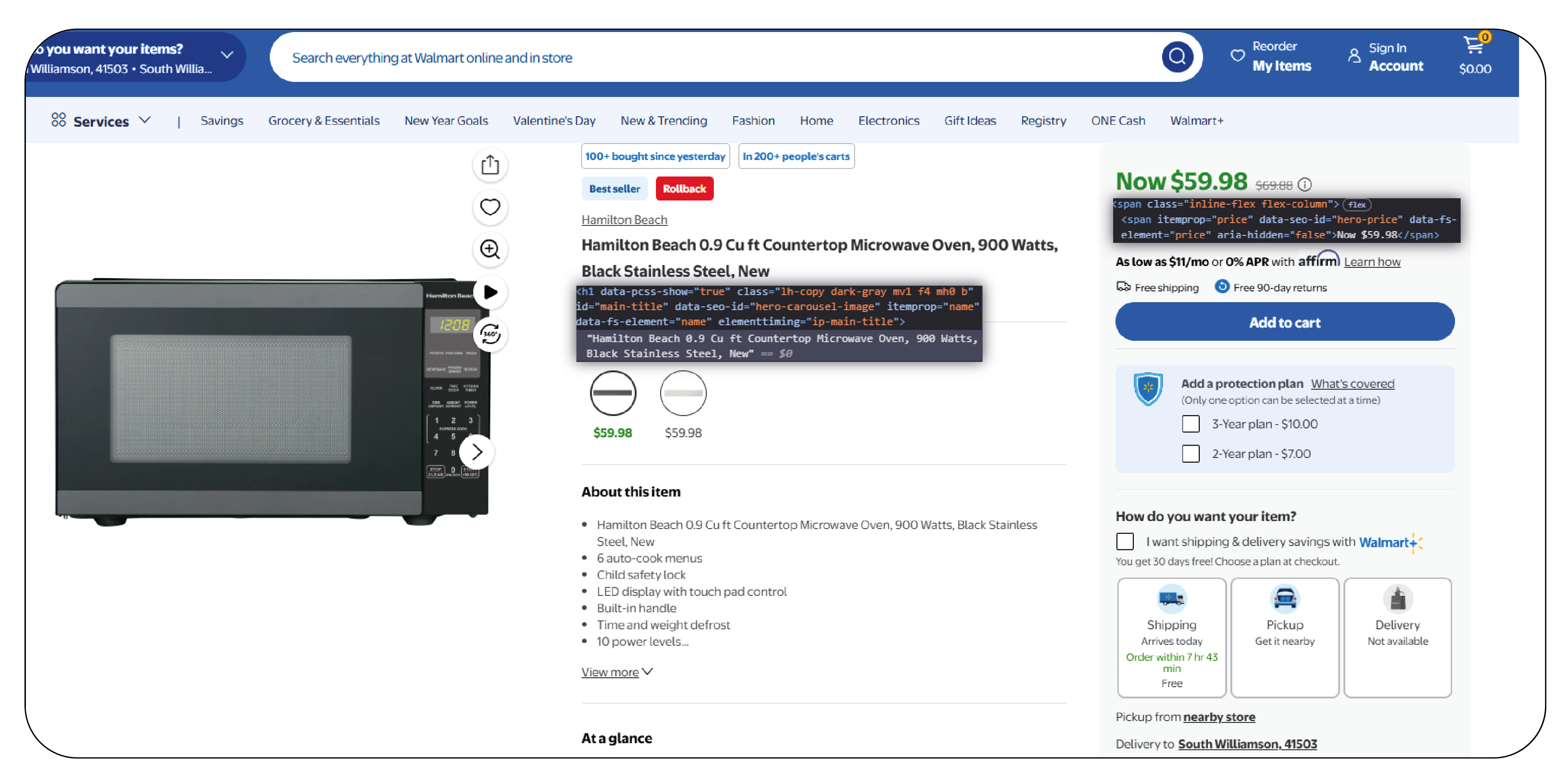
Web scraping refers to the process of extracting data from websites. It involves retrieving
content from web pages (HTML, JavaScript, and other types of data) and then processing or
converting it into a usable format such as JSON, CSV, or an Excel sheet. On the other hand,
Regular Expressions (RegEx) is a powerful tool used to identify, match, and manipulate strings
based on patterns. RegEx provides a flexible and concise syntax for pattern matching, allowing
it to handle various data types and formats. Scraping data using regular expressions, when
combined with web scraping, becomes highly effective for targeting specific data in HTML code,
such as email addresses, phone numbers, product descriptions, and other structured
information that follows a predictable pattern. This combination allows for more precise and
efficient web data extraction with RegEx, enabling web scrapers to extract only the most
relevant information from large datasets.
The Role of RegEx in Web Scraping

Regular Expressions (RegEx) serve as a powerful filtering mechanism in web scraping, enabling scrapers to parse through raw HTML content and extract specific elements that match predefined patterns. RegEx allows precision in identifying the elements of interest in a webpage by matching patterns like text or numerical values. For example, if a webpage contains various types of information—such as product names, prices, descriptions, or dates—RegEx can be used to target and extract only the relevant data, such as prices or product names, by looking for patterns like numerical values or specific HTML tags that enclose the desired information.
A Service Page showcases the power of Regular Expressions (RegEx) in extracting precise data from websites. It would highlight how RegEx can filter and parse raw HTML, efficiently collecting specific elements like product names, prices, email addresses, phone numbers, and more. For example, the page could demonstrate how RegEx targets product prices on an e-commerce site by recognizing patterns, such as numerical values within specific HTML tags. Additionally, it could illustrate how RegEx matches email addresses or phone numbers based on standard formats, streamlining data extraction. The page would also emphasize the advantages of automated web scraping through RegEx, such as faster data collection and greater accuracy.
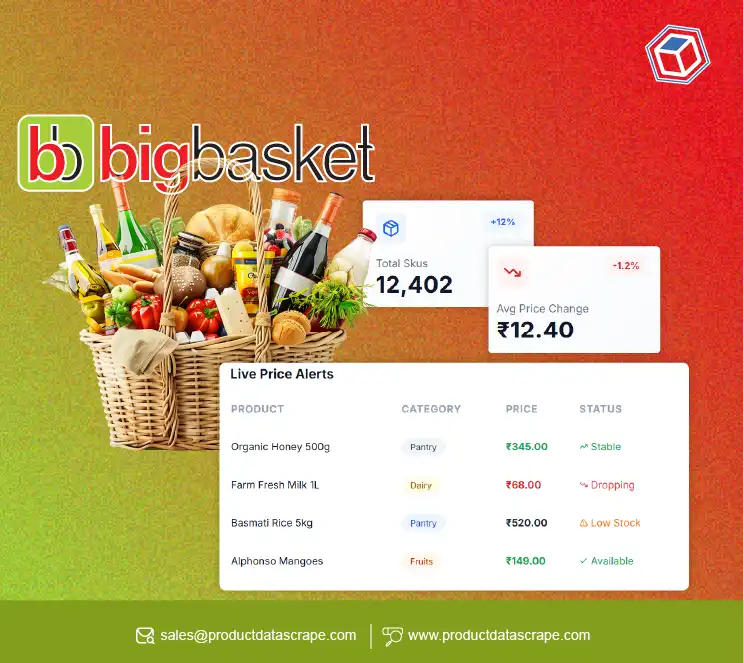
Offering E-Commerce Data Scraping Services with RegEx can help businesses stay ahead by providing real-time product data, competitive analysis, and comprehensive datasets to inform decision-making.
Common Use Cases for RegEx in Web Scraping

RegEx is a powerful tool in web scraping, enabling precise extraction of structured data from
websites. It simplifies targeting specific patterns such as email addresses, phone numbers,
product details, dates, and links, making data collection more efficient and accurate.
- Extracting Email Addresses: Email addresses follow a specific, recognizable pattern, usually in the format username@domain.com. RegEx is exceptionally effective at identifying this pattern across a webpage. By creating a suitable regular expression, web scrapers can quickly locate and extract email addresses embedded within the content of a webpage. This can be useful for tasks like gathering contact information or marketing lists. A RegEx data collection service can automate this process, making it faster and more efficient.
- Capturing Phone Numbers: Phone numbers can vary widely in format across different countries. However, RegEx identifies these numbers based on common patterns such as digits with or without dashes, parentheses, or country codes. For instance, a RegEx pattern can be designed to match formats like (123) 456-7890 or 123-456-7890. Using RegEx, web scrapers can consistently extract phone numbers from a page despite variations in format, making it an invaluable tool for data extraction from contact pages or customer support sites.
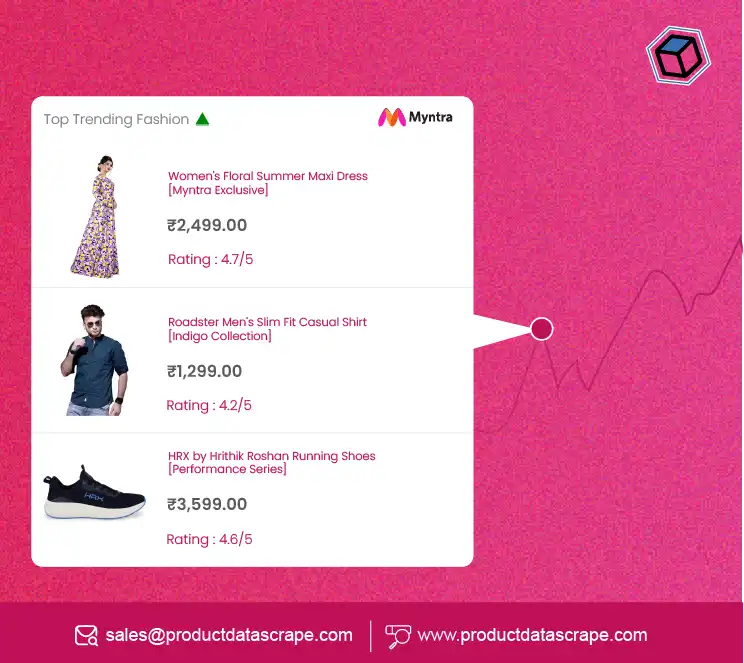
- Collecting Product Information: On e-commerce websites, RegEx is used to extract key product information like names, prices, descriptions, and other attributes. This data is often stored within specific HTML tags or classes, making it easy for RegEx to target and extract the relevant content. For instance, a RegEx pattern can be created to find product prices that are enclosed in
<span class="price"> tags or to capture product names listed inside <h1> or <h2> tags. This ability to isolate relevant product details is essential for building an E-Commerce dataset or monitoring price changes. Companies offering E-Commerce Data Scraping Services can use RegEx to streamline this process and gather comprehensive product information.
- Parsing Dates and Times: Dates and times are often displayed in a specific format on websites, such as MM/DD/YYYY or DD-MM-YYYY. RegEx can be used to identify these formats and extract date and time information from web pages. This feature benefits event listing pages, news articles, or blogs where dates and times are frequently mentioned. Using a regular expression to capture the date or time pattern, scrapers can efficiently collect this information in time-sensitive data analysis or event tracking.
- Extracting Links: Links are typically embedded in a webpage using
<a> tags with href attributes. RegEx can find and extract all URLs from a page by targeting these attributes. For example, a RegEx pattern can search for the href="URL" attribute within <a> tags, capturing the URL as part of the matched pattern. This makes it possible for web scrapers to gather all the links from a page for tasks like building site maps, aggregating resources, or conducting competitive analysis by identifying competitors' links.
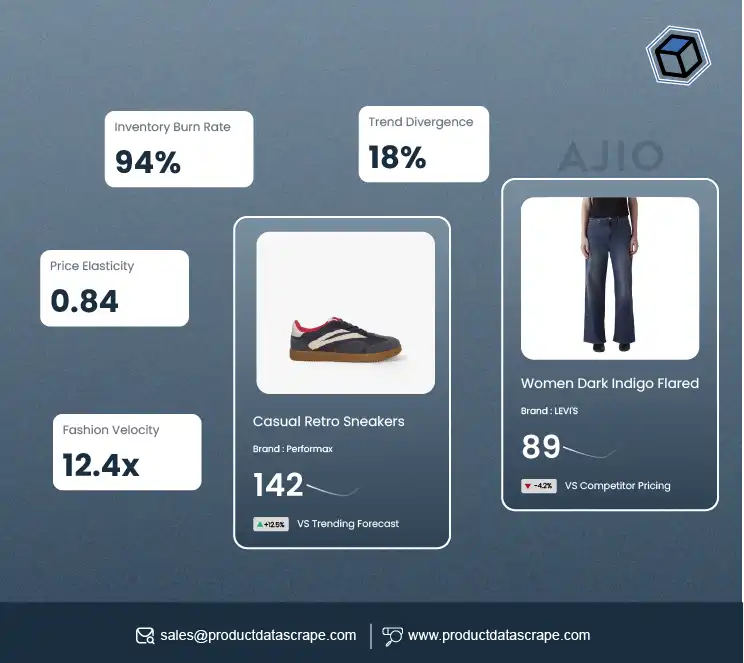
Advantages of Using RegEx in Web Scraping for E-Commerce
Using RegEx in web scraping for e-commerce offers significant advantages, including precise
product data extraction, pricing information, and customer reviews. It enhances efficiency,
accuracy, and automation, helping businesses gather valuable insights and stay competitive in
the online marketplace.
- Precision and Flexibility: RegEx efficiently identifies complex patterns in data, ensuring that only the most relevant content is scraped. RegEx can accommodate almost any matching requirement, whether a specific format, a set of keywords, or a combination of symbols. Additionally, its flexibility allows for modifications as the website structure changes without requiring a complete overhaul of the scraping code.
- Reduced Processing Time: RegEx can significantly reduce the time needed to locate specific elements when scraping large amounts of data. Since RegEx allows for direct pattern matching, eliminating the need for exhaustive searches or manual identification, leading to faster data extraction and processing.
- Reduced Dependencies: Unlike more sophisticated web scraping techniques that rely on parsing libraries or external dependencies (such as BeautifulSoup or Selenium), RegEx is lightweight and can be used directly within the scraping script. This makes the scraping process more efficient, especially when simple pattern recognition is sufficient.
- Handling Unstructured Data: Many websites contain unstructured data in their HTML code, such as extra spaces, line breaks, or embedded script tags. RegEx can cleanly extract the relevant content from messy or poorly formatted web pages, making it easier to process data even when it's not well-organized.
Key Challenges of Using RegEx in Web Scraping
While RegEx is a potent tool, using it for web scraping, especially for more complex websites,
presents particular challenges.
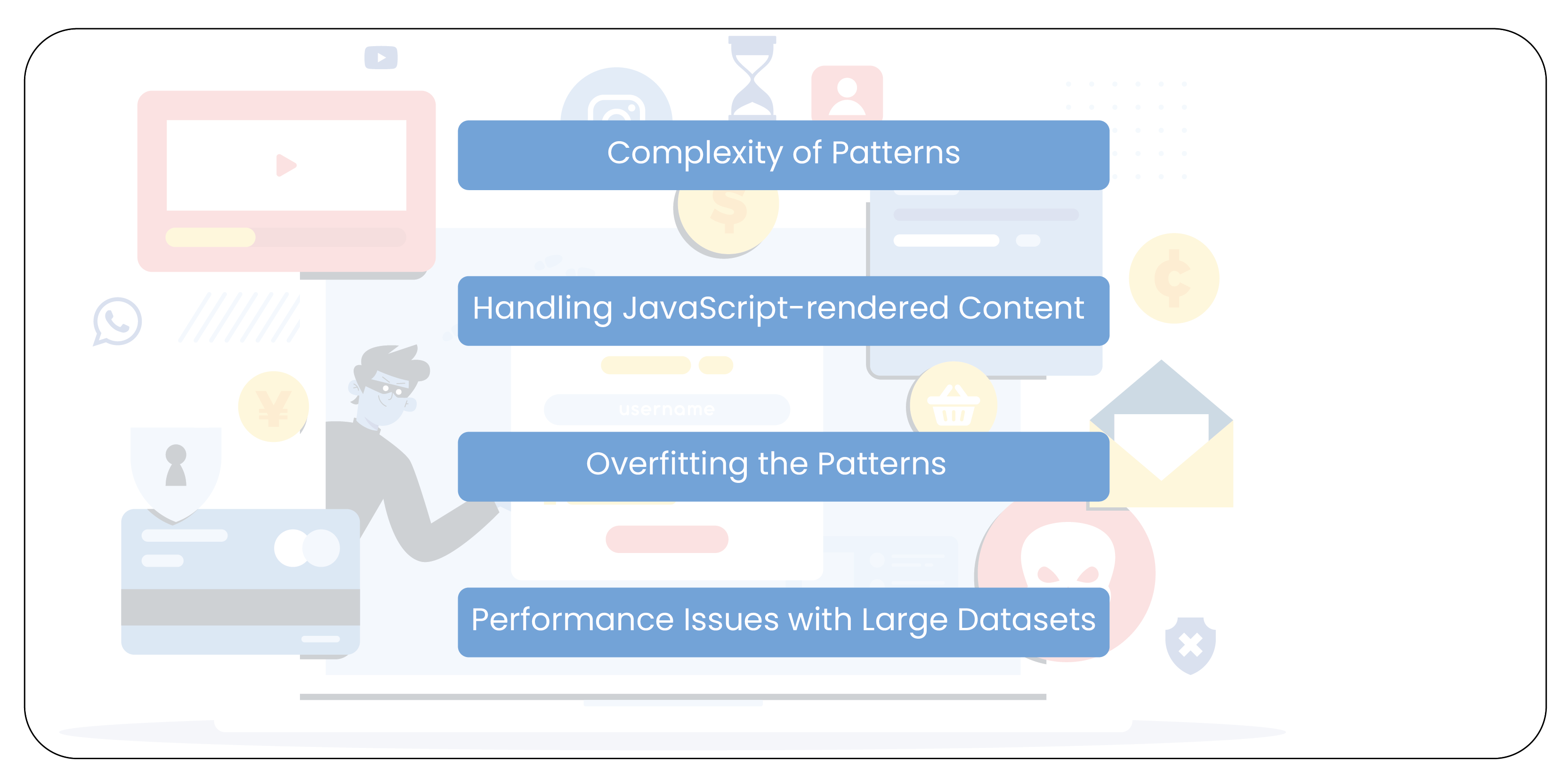
- Complexity of Patterns: As websites become more dynamic, the patterns within their HTML structure can grow increasingly complex. Web pages may have varying layouts, unpredictable elements, or frequently changing content. Creating a RegEx pattern that consistently captures the desired data across all pages can make it difficult. In such cases, building and maintaining RegEx patterns becomes a time-consuming process.
- Handling JavaScript-rendered Content: RegEx is great for scraping static HTML content but may struggle when scraping data rendered by JavaScript. Modern websites rely heavily on JavaScript to load content dynamically after the initial page load. In these cases, RegEx may not be sufficient to extract the required data unless additional tools like Selenium or Puppeteer are used to simulate browser behavior.
- Overfitting the Patterns: Another risk when using RegEx in web scraping is overfitting the patterns. If the RegEx pattern is too specific, it might work for one page but fail on others due to small changes in the page structure. This could result in missing valuable data or even scraping irrelevant content. Therefore, it's essential to test and refine the regular expression to ensure it's as adaptable as possible to variations in website design.
- Performance Issues with Large Datasets: When scraping extensive data from complex web pages, RegEx can become inefficient if the patterns are not optimized. For example, overly broad patterns or unnecessary backtracking can lead to performance degradation. Building efficient and precise RegEx expressions is crucial to avoid slowdowns and reduce processing time.
Best Practices for Using RegEx in Web Scraping
To maximize the benefits of RegEx in web scraping while minimizing potential issues, consider
the following best practices:
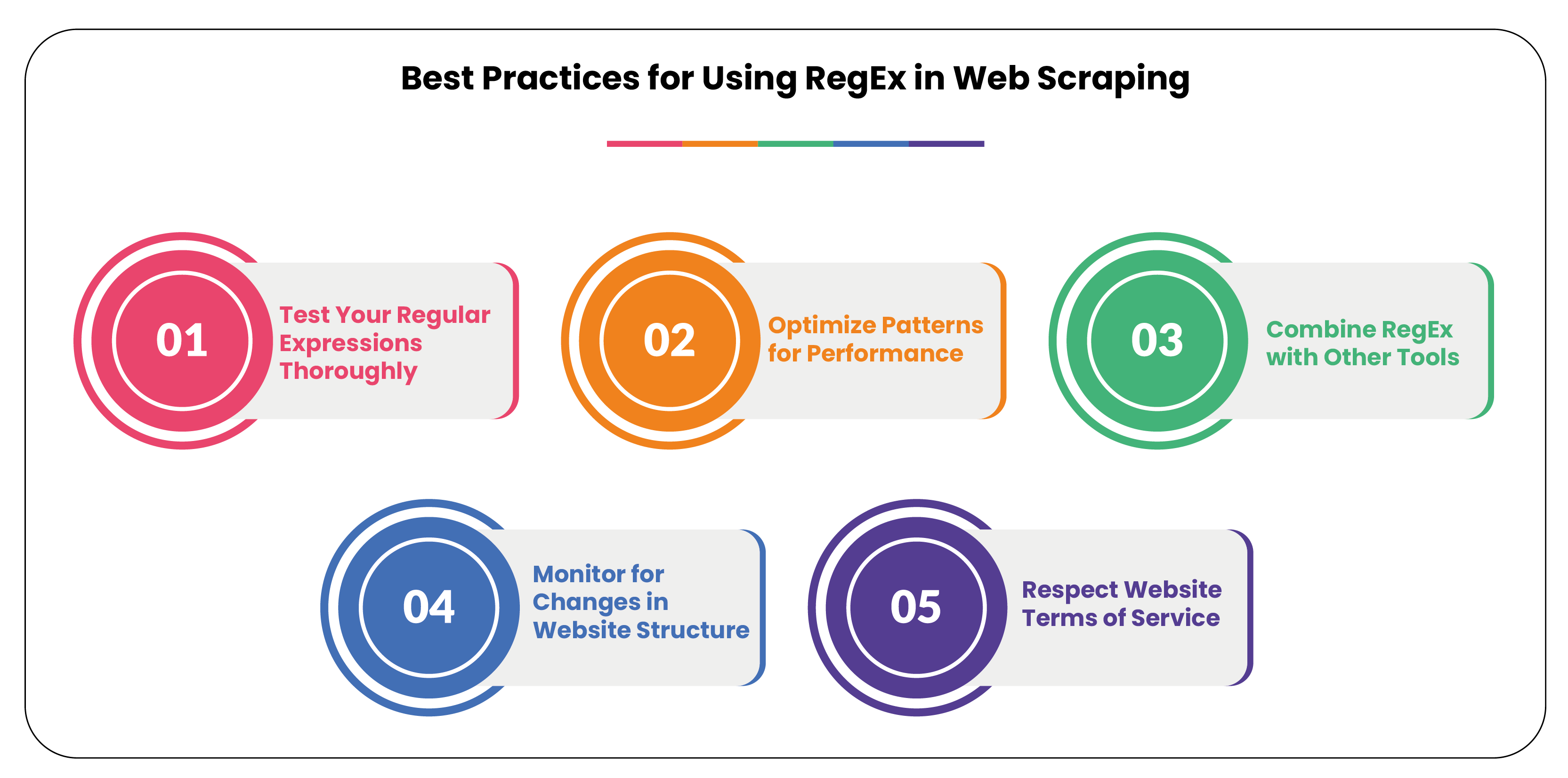
1. Test Your Regular Expressions Thoroughly: Before deploying your RegEx patterns to scrape live websites, always test them on a small sample of data to ensure they match the correct content. Tools like regex101.com can be invaluable for writing, debugging, and testing regular expressions.
2. Optimize Patterns for Performance: Regular expressions can be computationally expensive, especially when dealing with large datasets. Avoid overly broad patterns, and make your expressions as specific and efficient as possible. This will improve the scraping speed and minimize the load on the server.
3. Combine RegEx with Other Tools: For complex scraping tasks, combine RegEx with other web scraping tools like BeautifulSoup, lxml, or Scrapy. These tools are designed to parse HTML and XML documents, making navigating the DOM (Document Object Model) structure easier. RegEx will then be applied to extract precise content.
4. Monitor for Changes in Website Structure: Websites and patterns in the HTML code change frequently. Regularly review and update your RegEx patterns to ensure they still capture the desired data after website updates or changes to the page structure.
5. Respect Website Terms of Service: When scraping data, always comply with the website's terms of service, as scraping can sometimes violate those terms. Ensure ethical scraping practices, such as limiting the frequency of requests to avoid overloading the server.
Conclusion
Web scraping using RegEx is a highly effective approach for extracting targeted data from websites with a defined structure. With the ability to match complex patterns and collect information with precision, RegEx plays an indispensable role in web scraping, whether it's for competitive analysis, data mining, or research. Despite its challenges, including the potential for complex patterns and performance issues, RegEx remains a powerful tool for eCommerce Dataset Scraping with careful planning and best practices.
By leveraging RegEx, web scraping can be more efficient, precise, and flexible. This enables businesses and developers to gather actionable insights from vast online data and make more informed decisions.
At Product Data Scrape, we strongly emphasize ethical practices across all our services, including Competitor Price Monitoring and Mobile App Data Scraping. Our commitment to transparency and integrity is at the heart of everything we do. With a global presence and a focus on personalized solutions, we aim to exceed client expectations and drive success in data analytics. Our dedication to ethical principles ensures that our operations are both responsible and effective.



































.webp)





