
Scraping fashion clothing website data involves collecting information from
online fashion retailers' websites. This data may include product details, prices, images,
descriptions, customer reviews, etc. It is a valuable process for market research, price
tracking, trend analysis, and competitive intelligence in the fashion industry. Businesses and
individuals can gain insights into fashion trends, pricing strategies, and consumer preferences
by leveraging e-commerce data scraping services, enabling better-informed decision-making and
strategic planning.
About Zara

Zara is one of the most renowned global fashion brands under the ownership of
Inditex, a significant player in the distribution world. Their pioneering business model
encompasses everything from design and manufacturing to distribution and sales, with a strong
focus on meeting consumer needs.
Their overarching mission is to offer customers an outstanding shopping
experience, featuring the latest fashion trends at affordable prices and backed by top-notch
customer service. To achieve this goal, they remain committed to investing in cutting-edge
systems, infrastructure, and technology geared toward enhancing the online shopping experience.
This ongoing commitment reflects their dedication to evolving for the future and solidifying
their position as a leading global force in fashion e-commerce. Scrape Zara fashion brand to
gather product information, pricing data, and customer reviews for market research and analysis.
List of Data Fields
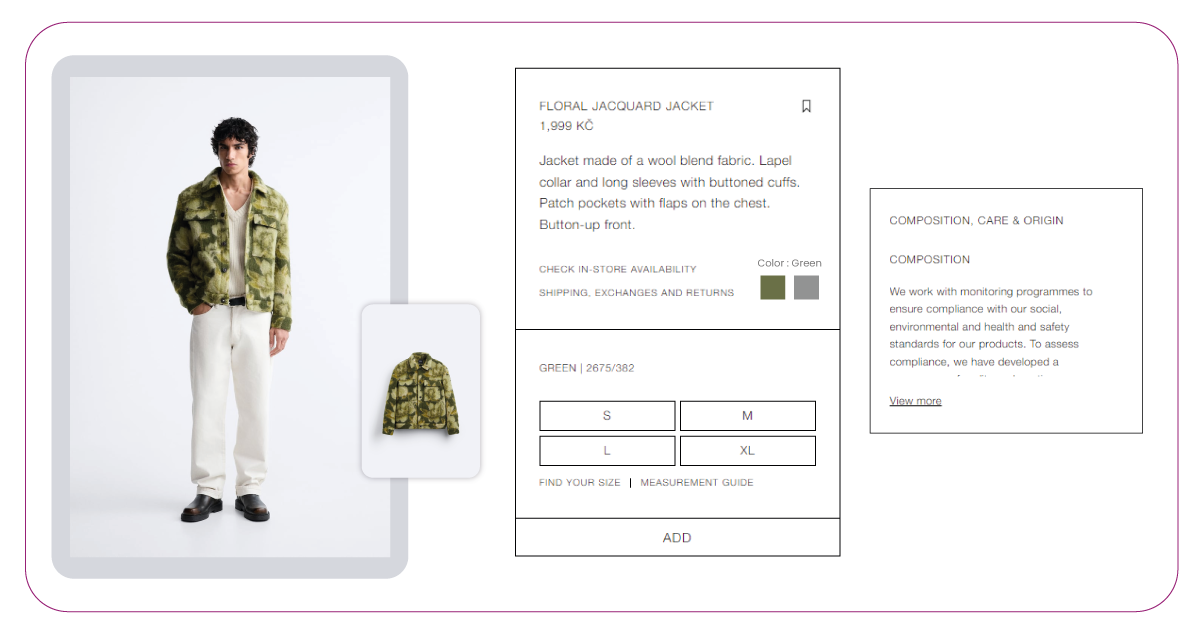
- Product name
- Product details
- Product SKU
- Total number of reviews
- Product Features
- Image URLs
- Product variations
- Product colors
- Product sizes
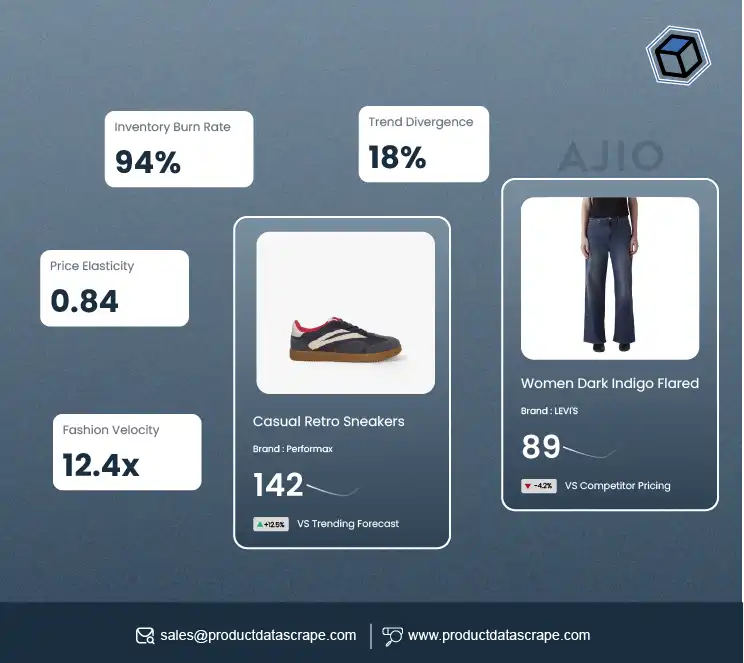
In the ever-evolving realm of fashion, staying abreast of the latest trends isn't merely a hobby; it's a necessity for many. And when we talk about trendsetting, Zara invariably becomes a focal point of the conversation. As a Spanish multinational clothing brand, this globally acclaimed brand has consistently left fashion enthusiasts eagerly anticipating its upcoming collections.
But what if there was a method to systematically analyze these trends, ensuring that we're catching up and predicting the next significant fashion wave? It is precisely where web scraping fashion data comes into play.
Zara houses a wealth of data that is key to comprehending the ever-shifting fashion trends, consumer inclinations, and market dynamics. This type of information is invaluable for making informed decisions.
This blog will delve into the art of scraping Zara's product data. We'll explore customer preferences, popular product selections, and price ranges within a specific Zara Women's Jackets category.
The Attributes
We will be extracting a set of key attributes from Zara's product pages, which include:
Product URL: This exclusive web address leads to a specific jacket on the Zara website.
Product Name: This attribute provides the name and model identification for the jacket.
MRP (Maximum Retail Price): This represents the selling price of the jacket.
Color: This attribute indicates the color of the jacket.
Description: It offers a concise overview or brief description of the jacket.
Step 1: Importing the Necessary Libraries
We must first import the essential libraries to scrape Zara fashion brand data using Python and Selenium. In this case, we will utilize Selenium, a powerful tool for automating web browser actions and scraping data from the Zara website. The libraries we need to import include:
Selenium Web Driver: This tool allows us to automate browser actions such as clicking buttons, filling fields, and navigating to different web pages.
By ClassWe'll use this to find web page elements with various strategies like class name, ID, XPATH, etc
Writer Class (from CSV Library): This class is for reading and writing tabular data in CSV format, which helps store the scraped data.
Sleep Function (from Time Library): We'll use the sleep function to introduce pauses or delays in program execution for a specified number of seconds, which can be beneficial when navigating and scraping web pages.

Step 2: Initialization Process
Following the importation of the necessary libraries, Zara product data scraping services must initiate several essential steps before commencing the scraping process. To begin, we initialize a web driver by creating an instance of the Chrome web driver and specifying the path to the ChromeDriver executable. This step is crucial as it establishes a connection with the web browser, which, in this case, is Google Chrome.
After initializing the web browser, launch a Google Chrome web browser window, and the Zara website is accessed using the get() function. This action is vital as it enables Selenium to interact with the website's content. Furthermore, we maximize the browser window's size using the maximize_window() function to ensure a comprehensive web page view.

Step 3: Retrieving Product Links
Zara's website operates as a dynamically loaded platform, meaning the products are loaded onto the webpage only when you scroll down. Initially, only a limited number of products are visible. To navigate through the page, we follow these steps:
First, we determine the initial height of the webpage and store this value in a variable named 'height.'
Then, we enter a loop where we repeatedly scroll to the bottom of the page using a JavaScript command. After each scroll, we pause for 5 seconds to allow the content to load fully.
Inside the loop, a script calculates the new height of the page after each scroll and compares it to the initial height. Load all content if they match, and terminate the loop. It ensures we've retrieved links to all the available products on the webpage.

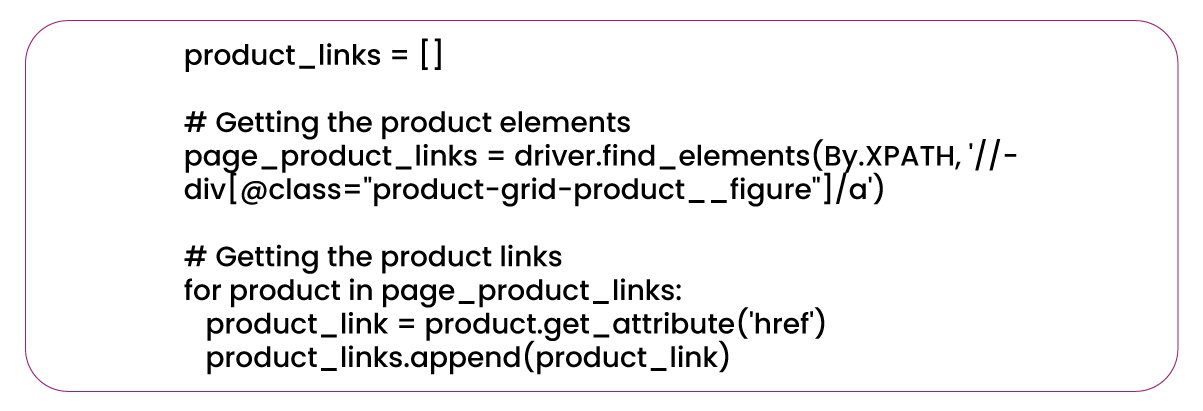
Once we load all the products, we create an empty list that stores the product links. To identify and extract the product elements from the web page, we employ XPath and the find_elements() function for this purpose. This function retrieves the product elements and returns them as a list.
We iterate through the list and utilize the get_attribute() method for each element to obtain the actual product links from these elements. This method allows us to extract the 'href' property corresponding to each product and store it in the previously created list. This process ensures that we collect all product links for further scraping and analysis.
Step 4: Function Definitions
Our next step involves defining functions that will allow us to extract each desired attribute. These functions will retrieve specific information from the product pages, making our clothing data scraping process more structured and organized.

Step 5: Writing to a CSV File
Now, let's explore how to store the extracted data in a CSV file for future use, such as analysis.
First, we open a file named "women_jacket_data.csv" in write mode and initialize an object of the writer class, which we'll name "theWriter." We define the column headings as a list to structure our data effectively. These headings will serve as the headers for different columns in the CSV file.
Subsequently, we write these column headings to the CSV file using the writerow() function.
Next, we initiate the process of extracting information about each product. We iterate through each product link stored in the "product_links" list to achieve this. We invoke the get() function and the previously defined functions for each link to extract the desired attributes.
Store the attribute values as a list for each product. Then, we write this list into the CSV file using the writerow() function, effectively creating a new row for each product's data.
Once this process is for all the products, we call the quit() command, which closes the web browser opened by the Selenium web driver.
We incorporate the sleep() function at intervals between different function calls. Add these pauses to avoid potential issues like being blocked by the website during the scraping process.

Conclusion: In the ever-evolving fashion industry, staying attuned to consumer preferences and emerging trends is paramount for brands striving to establish a formidable presence. This guide has demonstrated the art of web scraping Zara with Python and Selenium and underscored its adaptability for diverse product categories and e-commerce platforms using the Zara scraper. By harnessing this technique, brands can gain a competitive advantage and glean valuable insights into the ever-changing consumer demand landscape and style trends.
At Product Data Scrape, we maintain the highest ethical standards in all
operations, including Competitor Price Monitoring Services
and Mobile App Data Scraping. With a global presence spanning multiple offices, we consistently
deliver exceptional and honest services to meet the diverse needs of our valued customers.



































.webp)





