
Walgreens, a prominent pharmacy chain in the United States, offers more than just health products—it's a rich data source waiting for exploration. For those interested in unraveling the intricacies of online retail or gaining insights into consumer healthcare trends, web scraping is an invaluable tool.
Web scraping, the process of extracting data from websites, is a powerful method for collecting product information from online retailers. It streamlines data collection, opening doors to analysis and innovation. In this guide, we will take you through scraping Children's and baby's products from Walgreens, using the popular Python library Beautiful Soup.
We aim to retrieve crucial product details, such as product names, brands, ratings, review counts, unit prices, sale prices, sizes, and stock statuses. We will also delve into product offers, descriptions, and specifications and check for warnings or product ingredients. From setting up the scraping environment to writing the code for data extraction, we will explore the capabilities of Beautiful Soup and its role in data retrieval.
Data Attributes for Walgreens Web Scraping
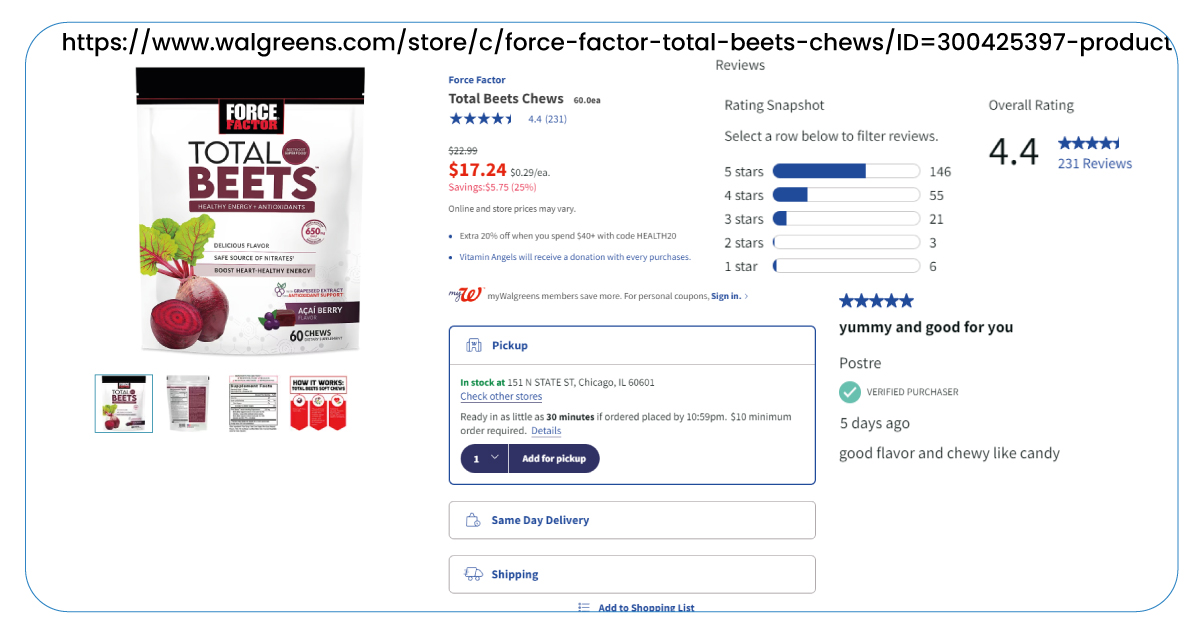
In this tutorial, we will extract retail data attributes from individual product pages on Walgreens:
Product URL: The web address of the products.
Product Name: The name of the products.
Brand: The brand associated with the products.
Number of Reviews: The count of product reviews.
Ratings: These include the product ratings by customers.
Price: The cost of the products.
Unit Price: The price per unit of the products.
Offer Availability: Information regarding any special offers or discounts.
Sizes/Weights/Counts: Details about the product's sizes, weights, or counts.
Stock Status: Information indicating the product's availability.
Product Description: A description providing insights into the products.
Product Specifications: Additional product details, including type, brand, FSA eligibility, size/count, item code, and UPC.
Product Ingredients: Information about the product's formulation and potential benefits.
Warnings: It includes safety-related information associated with the product
Importing Necessary Libraries
The initial step to scrape Walgreens with Python involves equipping ourselves with essential tools. We achieve this by importing crucial libraries, including:
re: Utilized for regular expressions.
time: Enables controlled navigation.
warnings: Essential for alert management.
pandas: Empowers adept data manipulation.
BeautifulSoup: Employed for elegant HTML parsing.
webdriver: Facilitates seamless automated browsing.
Etree: Enables skillful XML parsing.
ChromeDriverManager: Expertly manages Chrome WebDriver control.
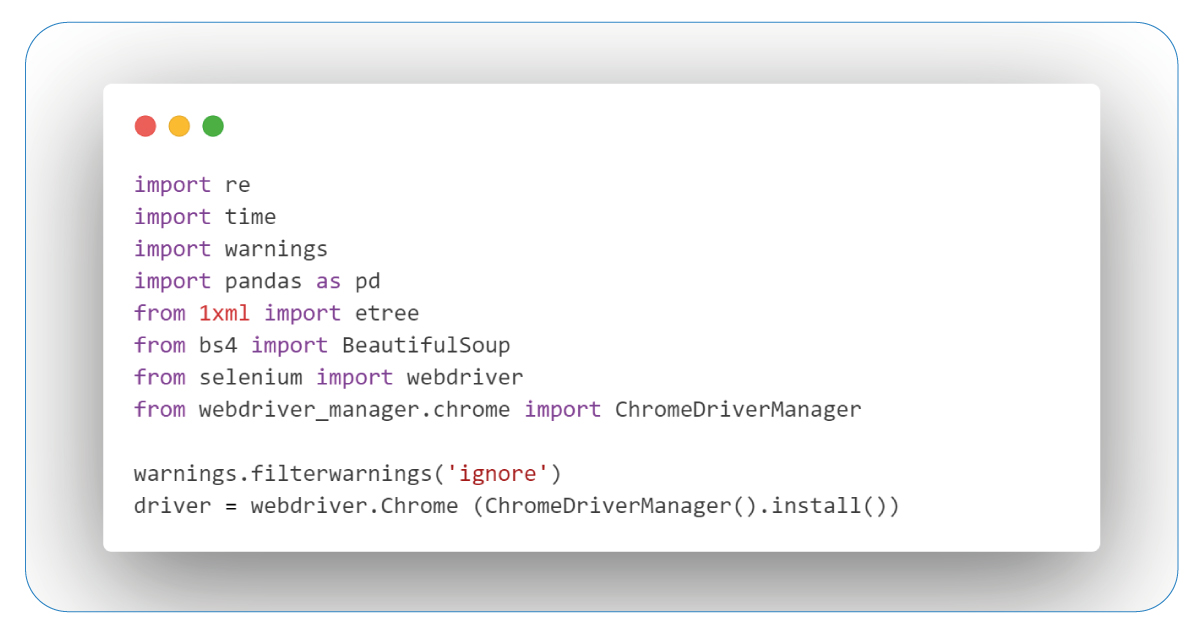
Request Retry Mechanism with Maximum Retry Limit
It is a vital strategy in web scraping. It allows retail data scrapers to persistently attempt data retrieval despite challenges, maintaining resilience with a set retry limit. This approach ensures reliable scraping in a dynamic online environment, adapting to issues like timeouts and network changes.
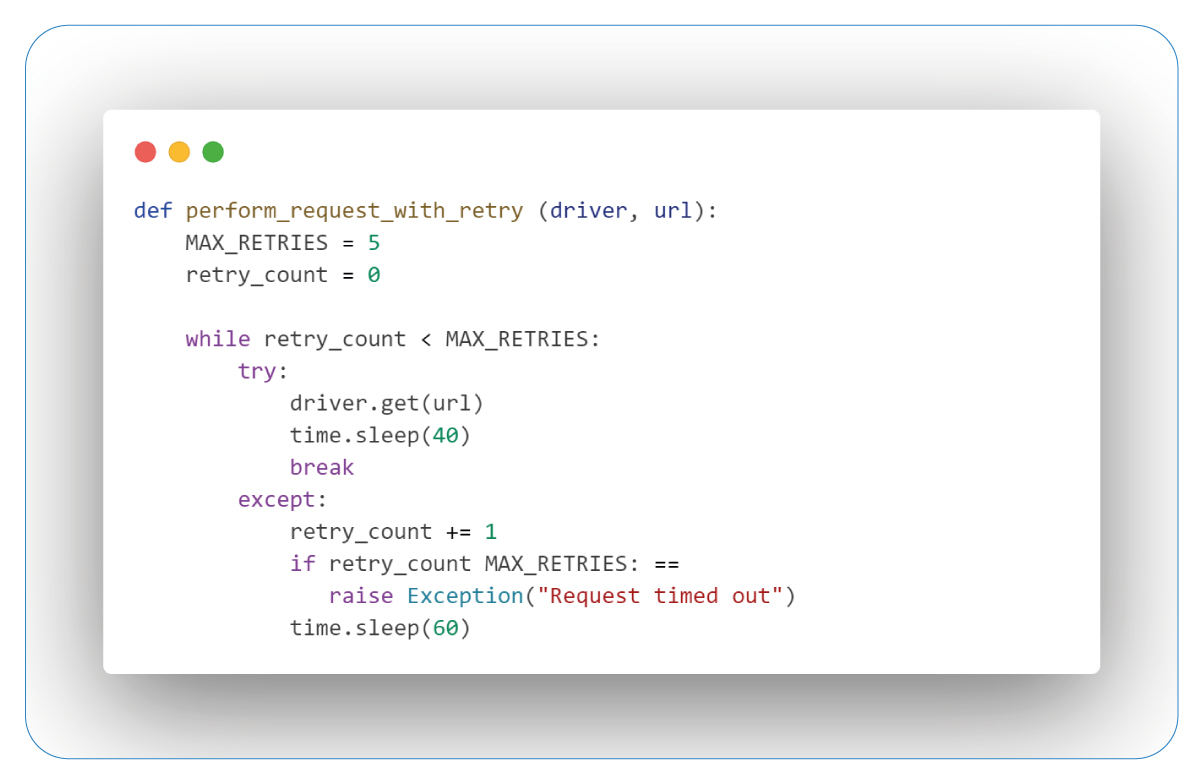
The "perform_request_with_retry" function takes two arguments: "driver," which represents a web driver instance, and "url," the target URL to access. It employs a retry mechanism with a predefined maximum limit of 5 retries.
Inside a loop, the function attempts to access the URL using "driver.get(url)." If successful, it pauses for 40 seconds to allow the page to load fully and exit the loop.
If an exception occurs during the attempt, the "retry_count" is increased. If "retry_count" reaches the maximum limit, it raises an exception with the message "Request timed out." Otherwise, it waits for 60 seconds before making another attempt. This approach prevents infinite retry loops and provides a buffer for resolving transient issues before the next attempt.
Extracting Content and Parsing the DOM
This step is pivotal as it involves the extraction and structuring of content from a particular webpage. While delving into data collection, this technique aids in comprehending webpage structures, transforming intricate HTML into an organized format, making it ready for in-depth analysis and further utilization.
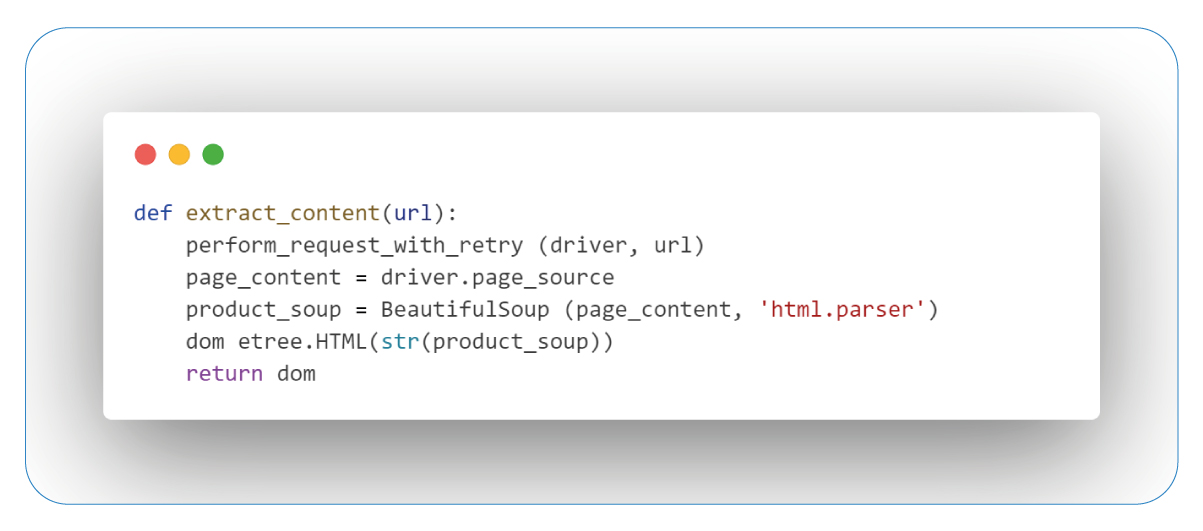
The 'extract_content' function is central to our web scraping workflow. It ensures a stable connection to the target webpage, captures the raw HTML content, and parses it into a structured format using Beautiful Soup. The result is the 'dom' object, which enhances manipulation capabilities and enables efficient navigation and extraction. This process equips us with practical tools to explore and utilize the website's content, uncovering valuable data for further analysis.
Retrieving Product URLs
The next essential step involves the extraction of product URLs from the Walgreens website. This process aims to collect and organize web addresses, each directing us to a unique product within Walgreens' digital store.
While not all of Walgreens' offerings may be visible on a single page, we simulate clicking a "next page" button, seamlessly transitioning from one page to another. This action unveils a wealth of additional product URLs. These URLs serve as keys, granting access to a realm of information. Our journey continues as we extract valuable details to create a comprehensive picture of the Children & Baby's Health Care section.
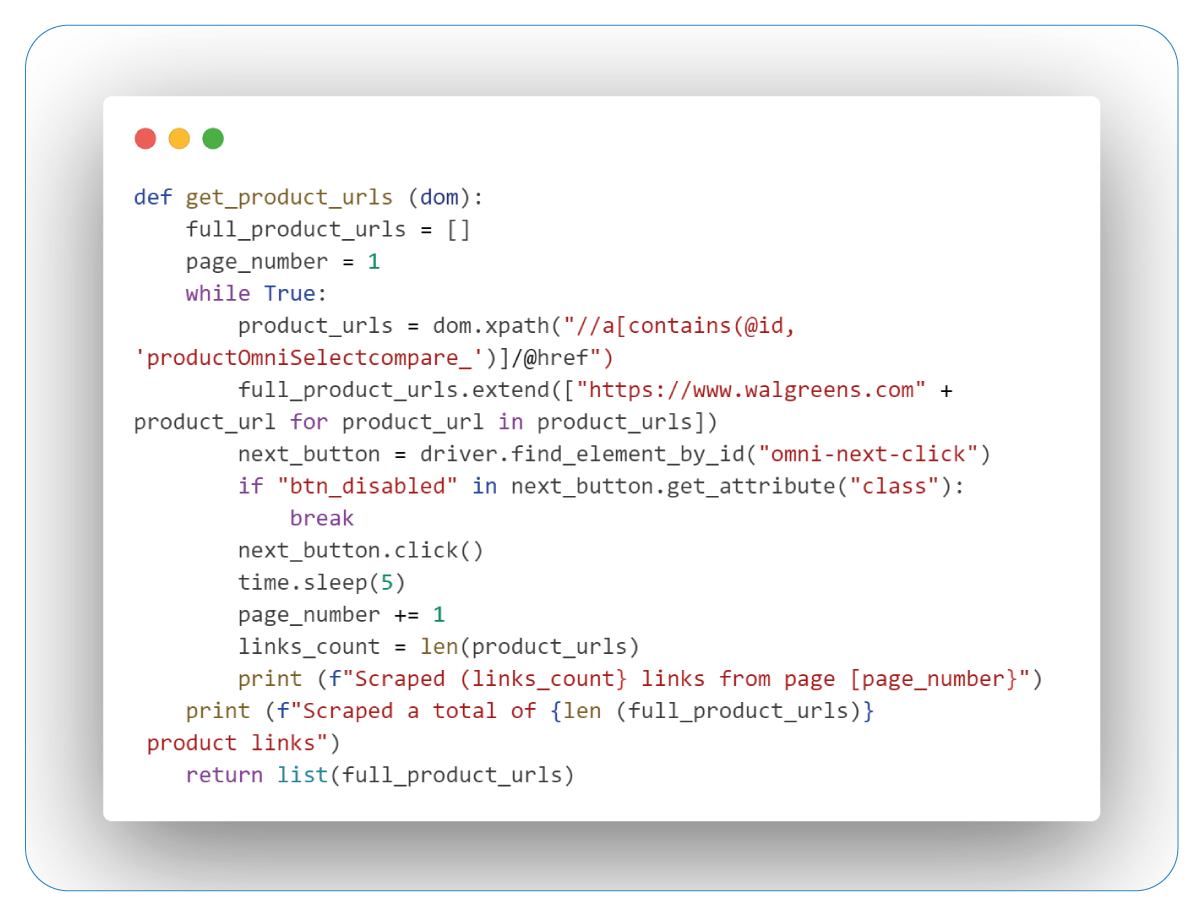
The "get_product_urls" function takes a parsed DOM object ("dom") as input, representing the webpage structure. Using XPath, it extracts partial product URLs based on specific attributes. Transform these partial URLs into complete URLs by combining them with the Walgreens site's base URL.
The function also handles pagination by simulating a "next page" button click to access more product listings. Before clicking, it checks if the button is disabled, indicating the end of available pages. After clicking, it briefly pauses to ensure the page loads before data extraction.
Upon completion, the function prints the total number of collected product URLs across all pages. These URLs are in the "full_product_urls" list, which serves as the function's final output for subsequent scraping processes.
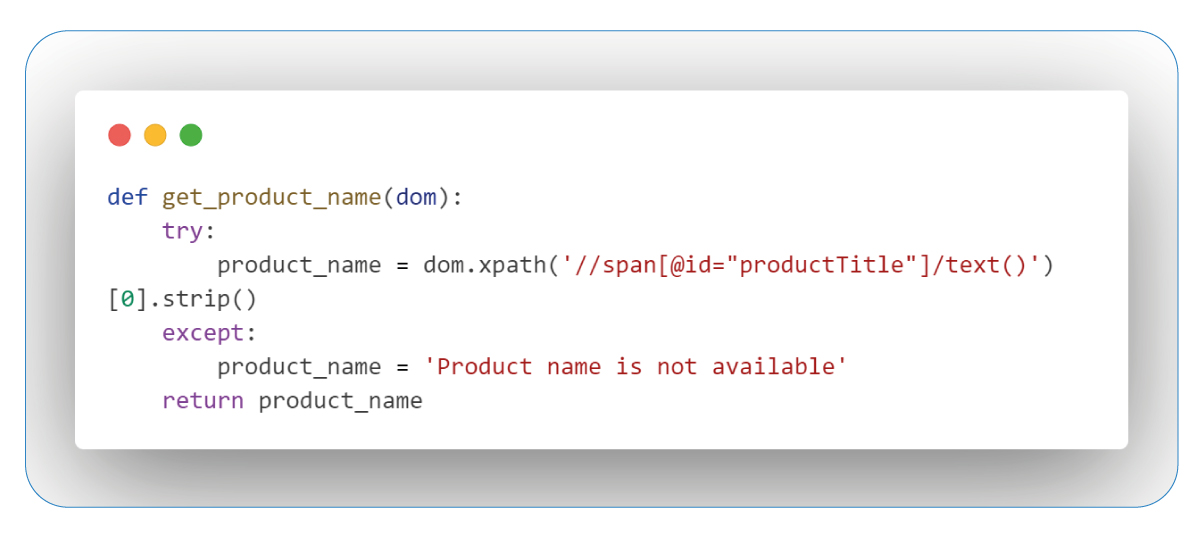
Retrieving Product Names
In the following step, our retail data scraping services focus on extracting the product names from the web pages, providing access to vital information—the product names. Each item possesses its distinct identity, rendering product names invaluable for a clear representation of the available offerings.
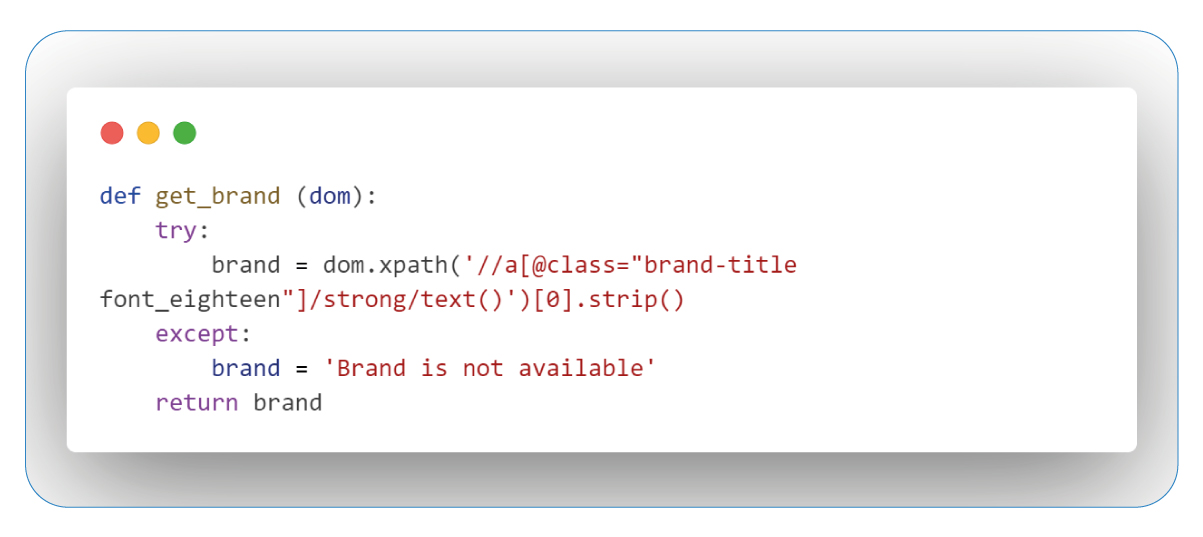
Retrieving Brand Names
The process of extracting brand names serves multiple purposes. It signifies product quality, builds trust, and offers valuable insights into consumer preferences and competitors. This data is instrumental in making informed decisions and enhancing our products, particularly in the Children & Baby's Health Care products category.
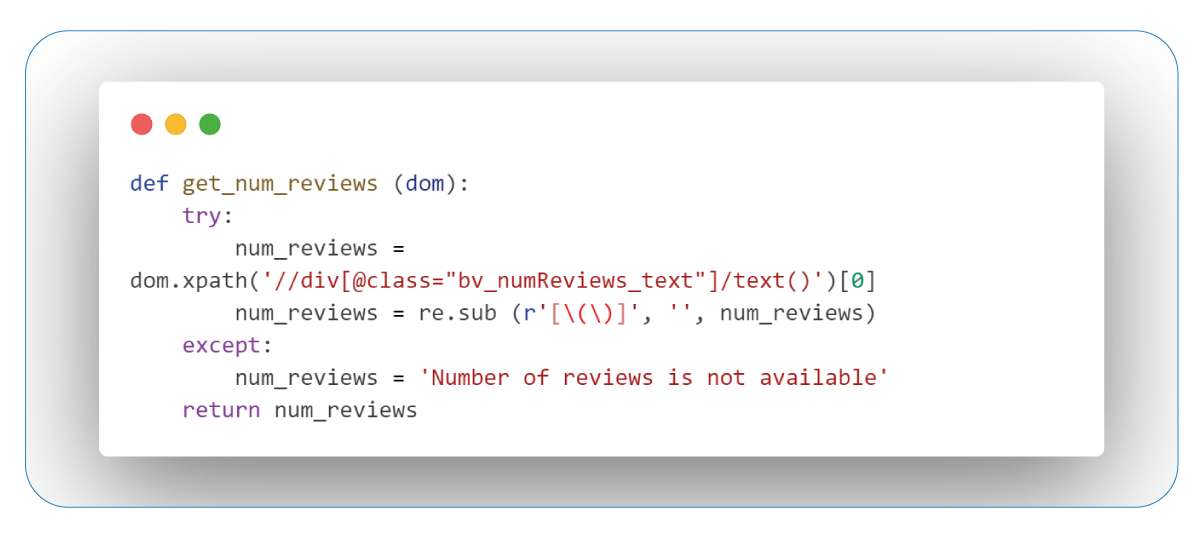
Retrieving Review Counts
Customer feedback holds significant value, and review numbers shed light on the popularity and satisfaction levels, particularly within Children's and baby's Health Care products. This insight empowers personalized choices and a deeper understanding of customer preferences in the realm of wellness.
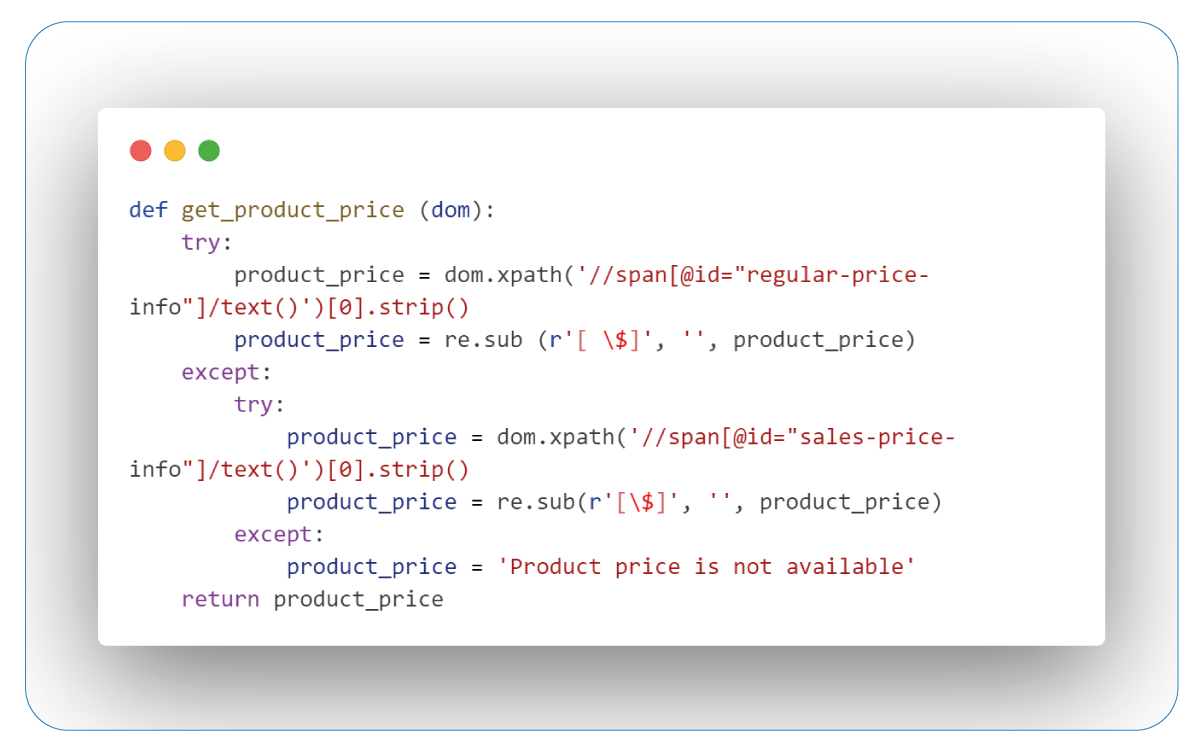
Retrieving Prices
The extraction of prices is pivotal for comparing costs in the realm of bargains and promotions. It equips us to make well-informed choices and discover opportunities for savings.
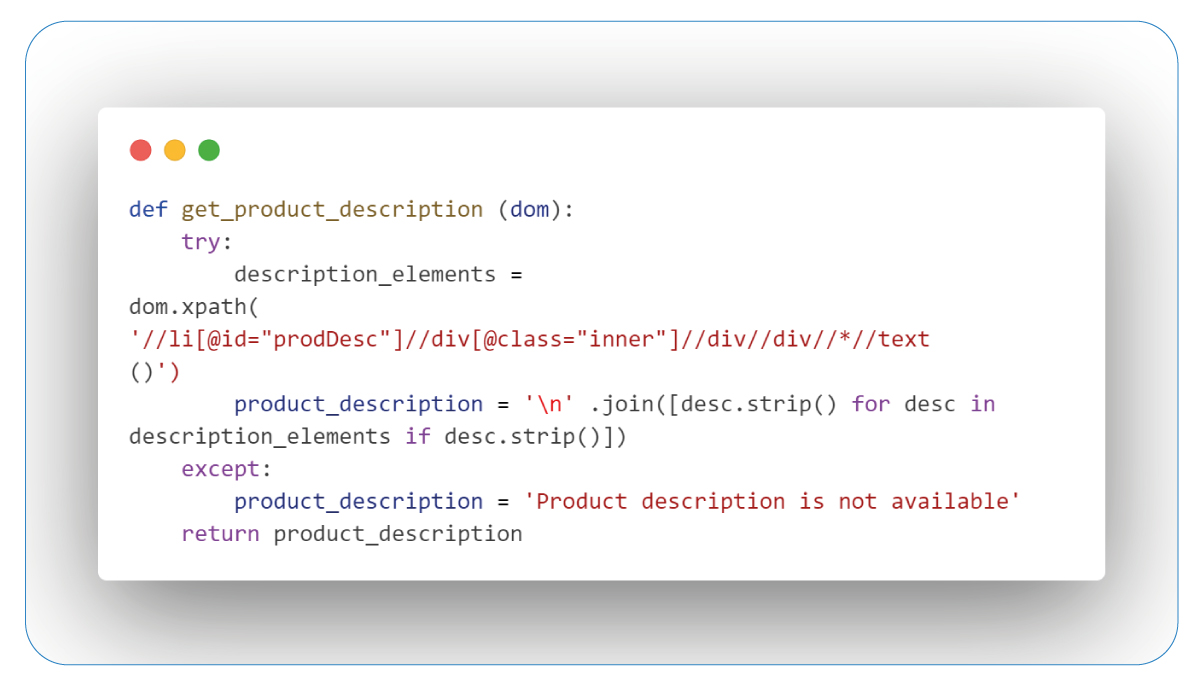
Retrieving Descriptions
The extraction of descriptions reveals the essence of products, providing valuable insights that empower informed decisions.
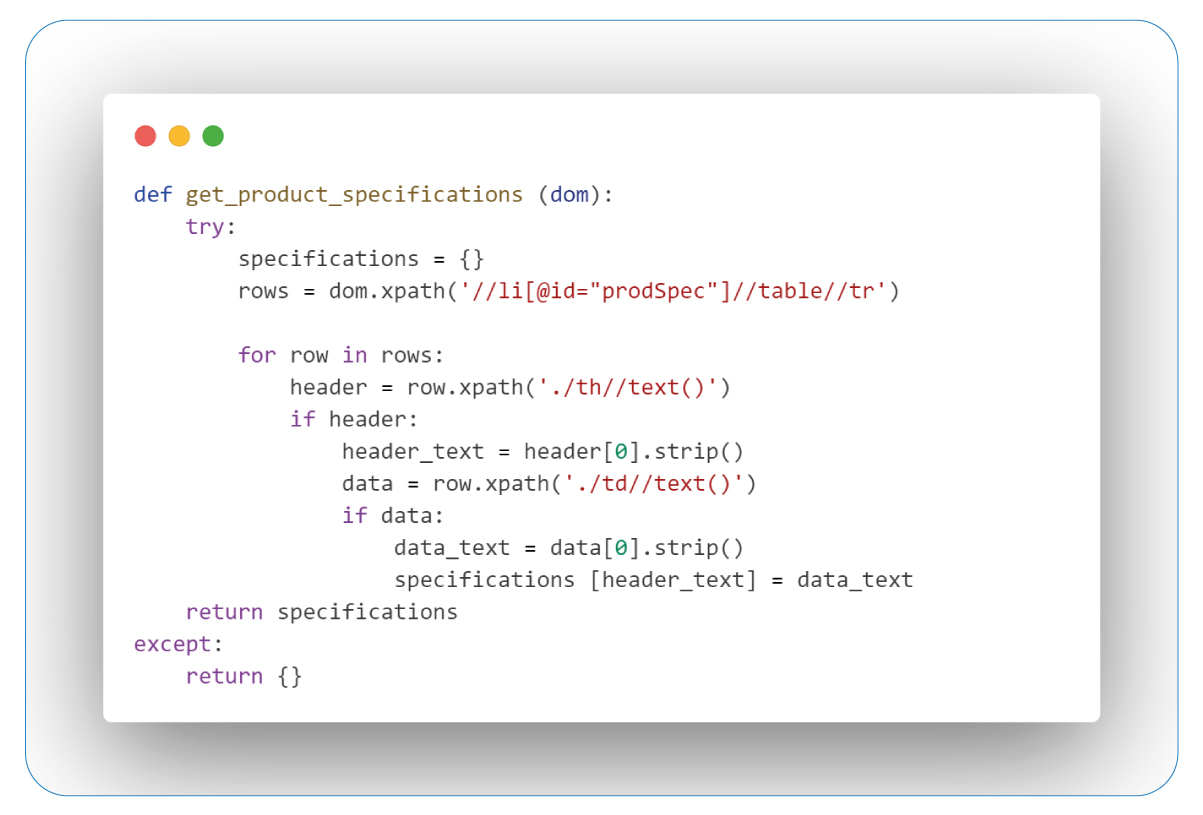
Retrieving Specifications
Specifications serve as the foundation for informed online shopping, offering a roadmap to product attributes that align with our preferences. These details, encompassing product type, brand, FSA eligibility, size/count, item code, and UPC, provide a comprehensive view of each item.
Extraction and Data Storage
In the subsequent stage, we execute the functions, capture the data, store it in an empty list, and save it as a CSV file.
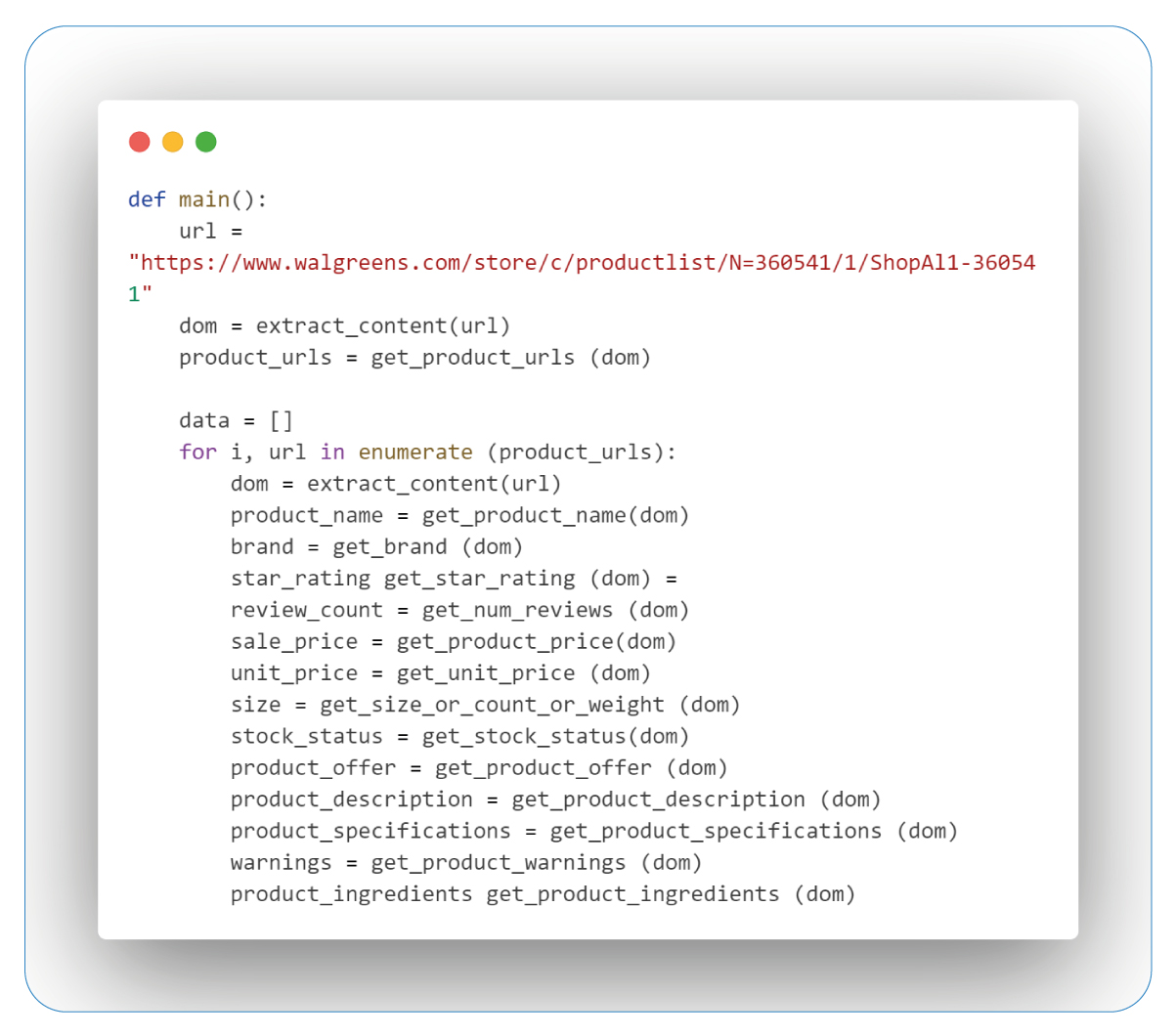

The "main()" function is the central orchestrator for web scraping product data from Walgreens. It specifies the target URL and then extracts the DOM content using the "extract_content" function. The "get_product_urls" function is employed to gather a list of product URLs from the webpage.
A loop iterates through each product URL, using various functions to extract specific attributes like name, brand, ratings, review count, pricing, size, availability, descriptions, specifications, warnings, and ingredients. This information is structured into a dictionary and added to the data list. The loop also includes conditional statements to provide progress updates and inform the user on achieving specific milestones.
Once all product URLs are processed, transform the collected data into a pandas DataFrame and export it as a CSV file named 'product_data.csv.' The web scraping driver is then shut.
The "if name == 'main':" block ensures that the "main()" function runs only on execution of the script, preventing execution from importing the script as a module. In summary, this script is a comprehensive guide for extracting and organizing diverse product-related data from Walgreens' web pages using Beautiful Soup and pandas.
Conclusion: Beautiful Soup simplifies web scraping, even for intricate websites like Walgreens. Following this step-by-step guide, you are well-prepared to scrape information about Children's and baby's Health Care products and extract valuable insights from the data. Always be mindful of website terms of use and guidelines while scraping, and embrace the journey of unlocking valuable insights from the web!
At Product Data Scrape, our commitment to unwavering ethical standards permeates every aspect of our business operations, whether our Competitor Price Monitoring Services or Mobile App Data Scraping. With a global presence spanning multiple locations, we unwaveringly deliver exceptional and transparent services to meet the diverse needs of our valued clients.







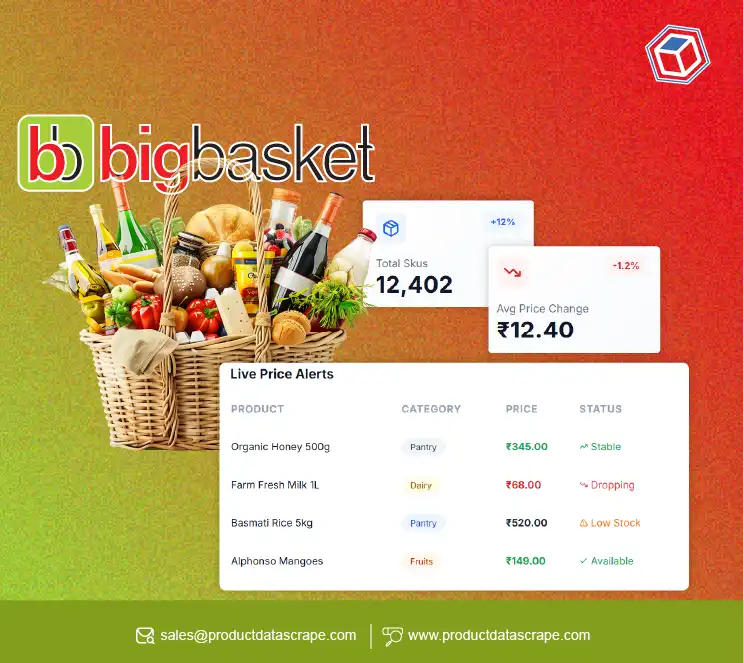
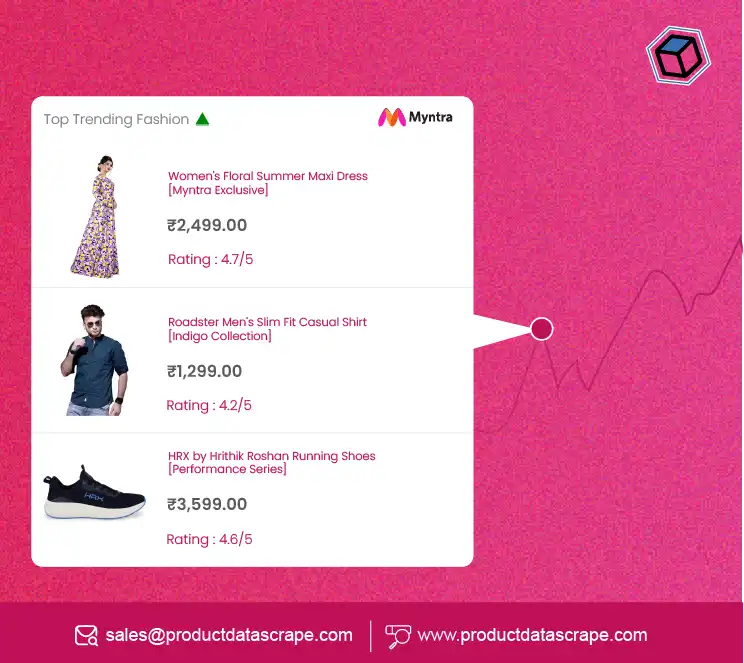
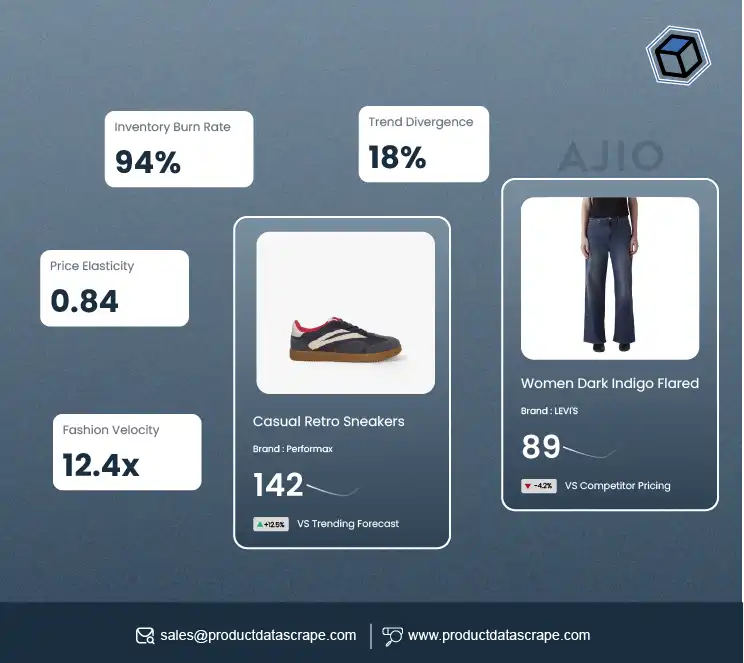




























.webp)





