
Dynamic websites generate real-time content through server-side scripts or database-driven API calls, making scraping more challenging than static sites. Sephora, a leading beauty retailer, offers a diverse product range, including its private label, accessible through its user-friendly online platform. This blog focuses on scraping data from Sephora, specifically lipsticks. Sephora's dynamic website tailors content to individual users' preferences, requiring user interactions for content generation.
Data scraping from ecommerce website proves invaluable for competitors and those seeking insights into Sephora's product catalog. Structured data simplifies product comparisons, trend tracking, and performance analysis. Selenium, a Python tool, facilitates dynamic website scraping by emulating user interactions, executing JavaScript, filling forms, and clicking buttons programmatically. Install the Selenium package and an appropriate web driver, like Chrome, Firefox, or Safari, to scrape dynamic eCommerce websites with Python.
Scraping Sephora Data with Python: A How-To Guide
We'll employ Python, Selenium, and BeautifulSoup to scrape data for lipstick from the Sephora website. The process details are available below:
Data Attributes:

- Product URL: Direct link to a specific product.
- Brand: The product's brand name.
- Product Name: The unique name identifying the product.
- Number of Reviews: The total count of product reviews.
- Love Count: The number of times the product has been "loved" by users.
- Star Rating: The average star rating given by customers.
- Price: The cost of the perfume.
- Shades: The lipstick shades.
- Type: The classification of the lipstick type.
- Formulation: Information about the lipstick composition.
- Size: Size details.
Import Necessary Libraries
To commence our data extraction from the Sephora website and effectively process the desired information, let's initiate by importing the essential libraries. These libraries serve distinct roles and enable various functionalities in our scraping operation including e-commerce price monitoring. Our toolbox encompasses:
The 'time' library facilitates the introduction of pauses into our script to prevent overwhelming the website with an excessive number of requests.
The 'random' library generates random numbers, injecting diversity into our requests for a more natural interaction with the site.
The 'pandas' library is a versatile tool for storing and manipulating the data we collect.
Our e-commerce data scraping services will harness the 'BeautifulSoup' module from the 'bs4' library to parse HTML and extract valuable data.
The 'Selenium' library is a powerful tool enabling us to take control of a web browser and engage with the Sephora website programmatically.
The 'webdriver' module, a crucial component of the Selenium library, empowers us to specify the browser we intend to use for our scraping tasks.
Additionally, we can tap into various extensions of the 'webdriver' module, including 'Keys' and 'By,' to access additional functionalities within the Selenium framework.
If any of these libraries are absent from your system, you can swiftly install them using the 'pip' command. Here's the code to import these indispensable libraries:
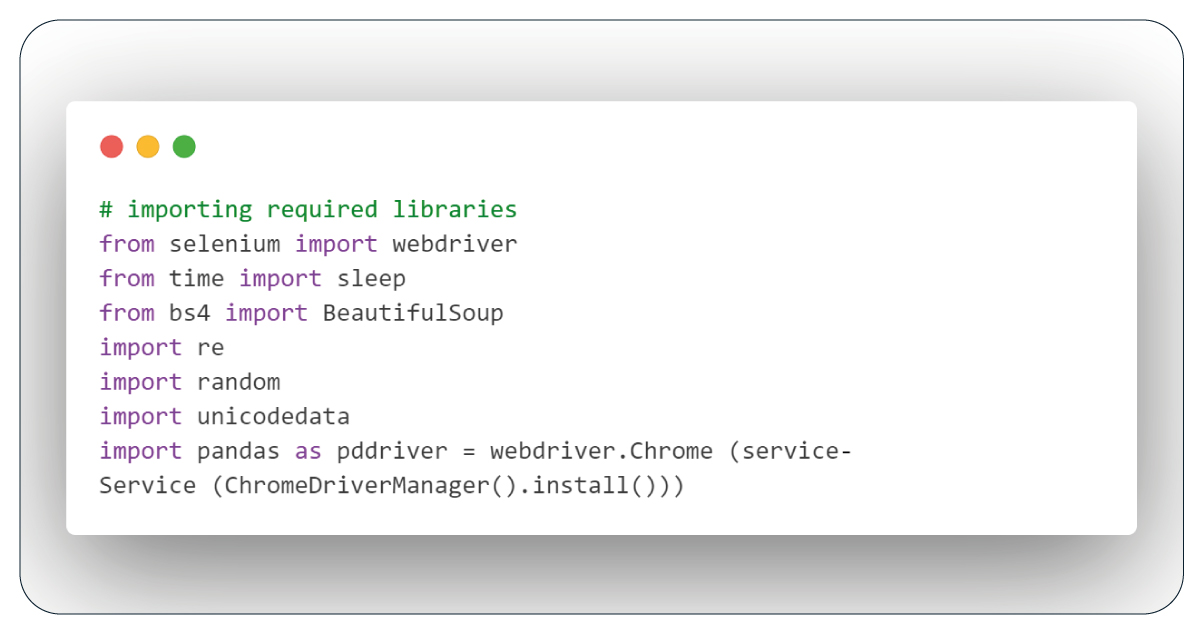
Next, we need to establish a Selenium browser instance. The following code accomplishes this task:
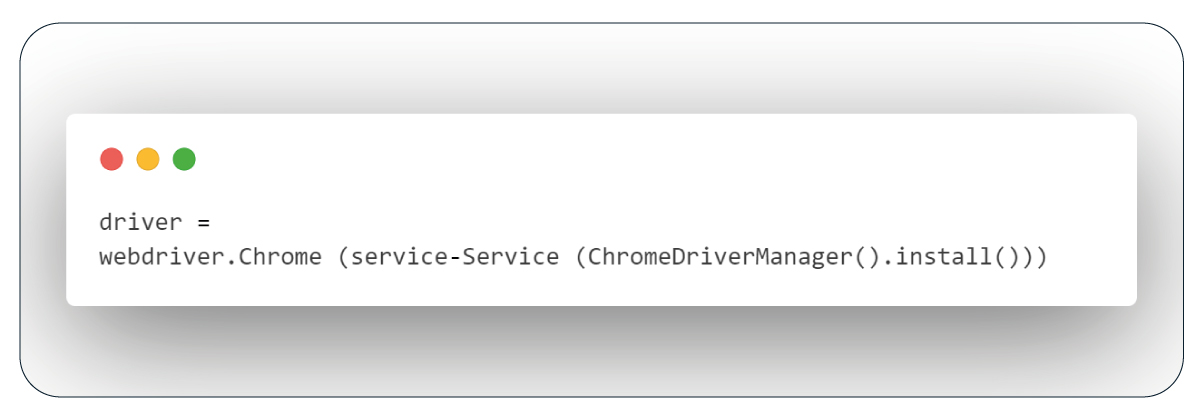
Introducing All Essential Functions:
To enhance the readability and maintainability of our code, we'll encapsulate specific tasks into reusable functions. These custom functions, termed user-defined functions, allow us to isolate particular actions and employ them multiple times within our script without redundant coding. By defining functions, our code becomes more structured and more accessible to comprehend.
Function: Delay
To introduce pauses between specific processes, we'll create a function that suspends the execution of the subsequent code for a random period ranging from 3 to 10 seconds. Invoke this function whenever we require a delay within our script.
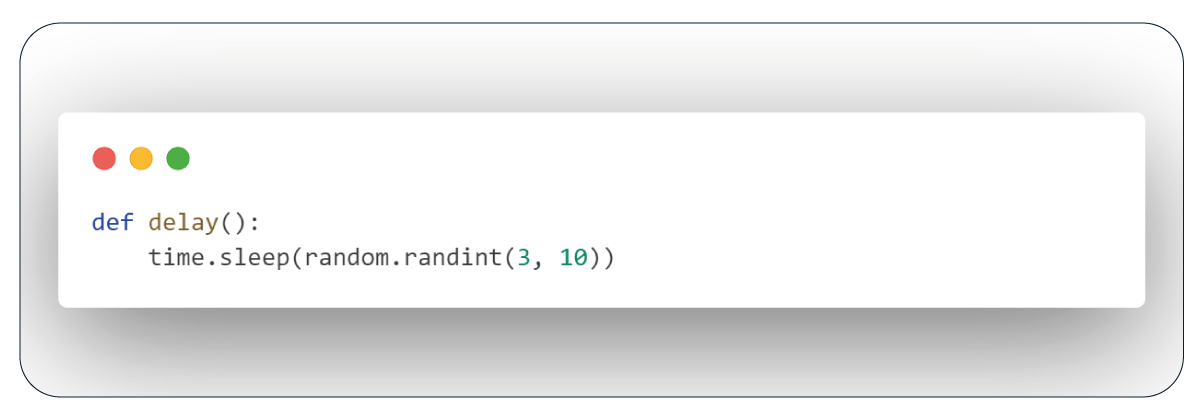
Function: Lazy Loading
To tackle lazy loading issues while scraping dynamic websites, we'll create a function that automatically scrolls down the page to trigger content loading. This function leverages the Keys class from the webdriver module to send page-down keystrokes to the browser whenever the body tag is detected. Additionally, we'll incorporate delays to ensure that the newly loaded content is correct.
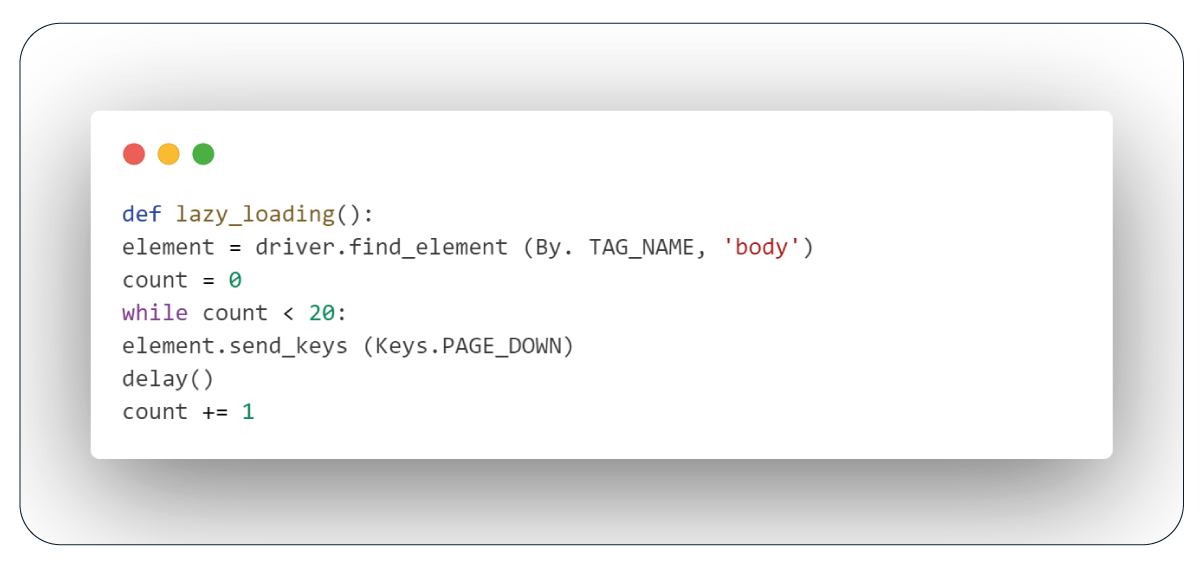
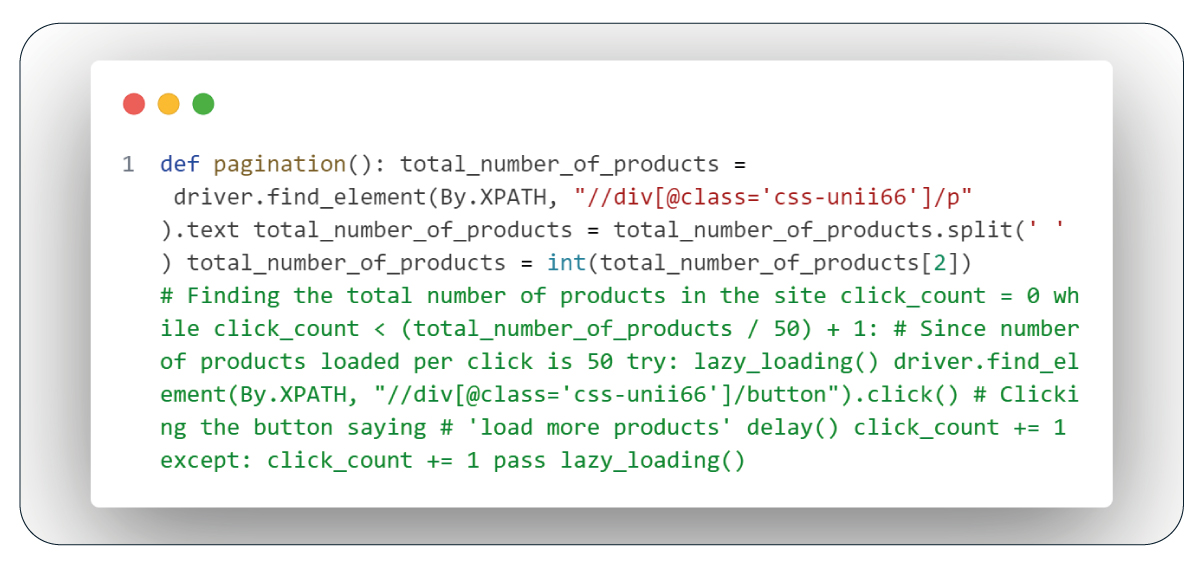
Function: Pagination
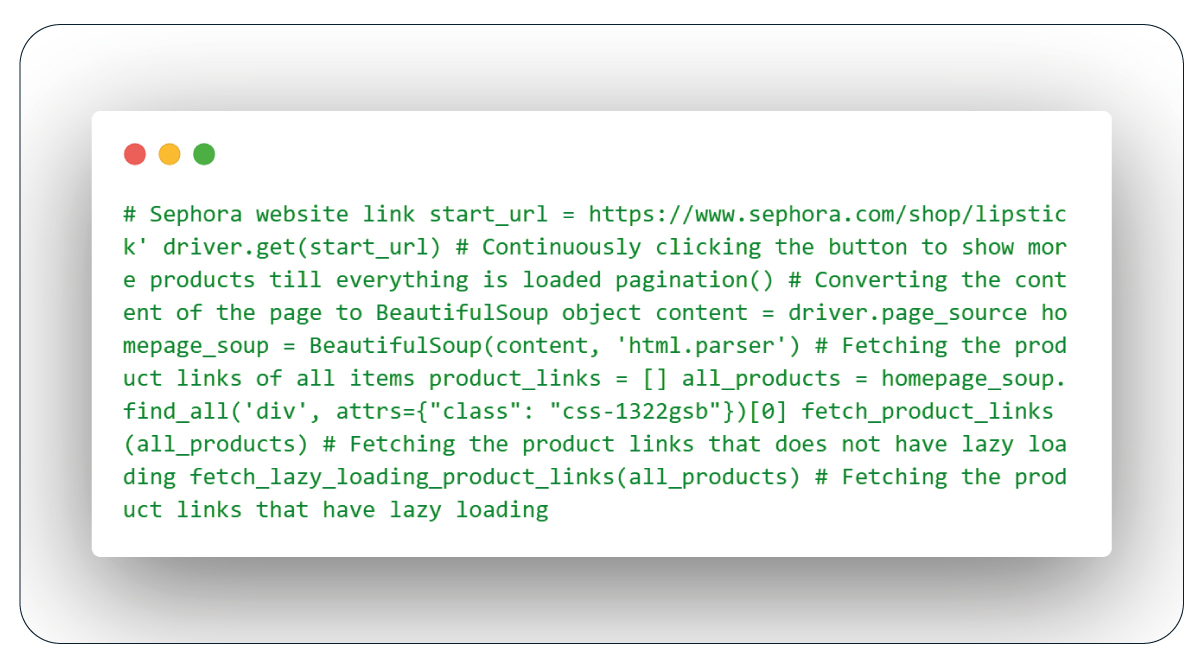
To access the complete list of products on Sephora's lipstick homepage, which initially shows only 60 out of around 192 items, we need to click the "Show More Products" button repeatedly. Each click loads an additional 50 products. To determine the number of clicks required, we locate the element containing the total product count using Selenium's webdriver and its XPath. We then calculate the number of times to click the button by dividing this count by 50. The lazy_loading function ensures proper loading of all products during this process.
Function: Fetch Product Links
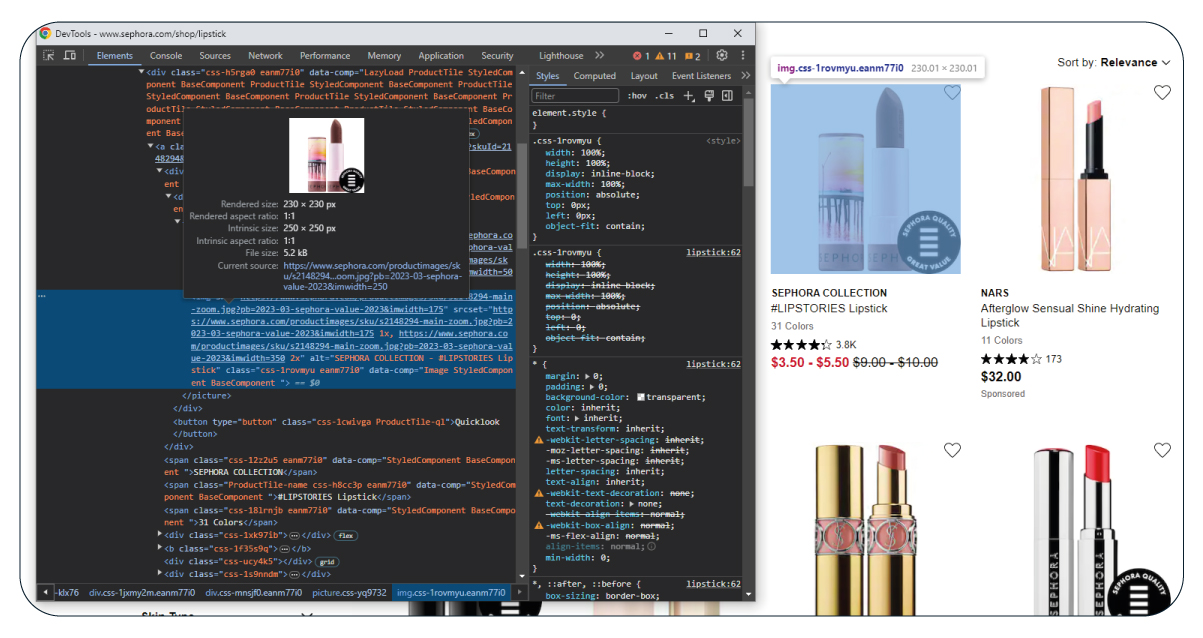
To extract product links from Sephora's lipstick page, we target items within the 'css-foh208' class, where links are within anchor tags with 'href' attributes.
Function: Get Non-Lazy Loading Product Links
Our e-commerce data scraper can create a function using Selenium to find elements with the 'css-foh208' class and extract the href attribute from the anchor tags within those elements. This function will gather the links, which is helpful for subsequent actions.
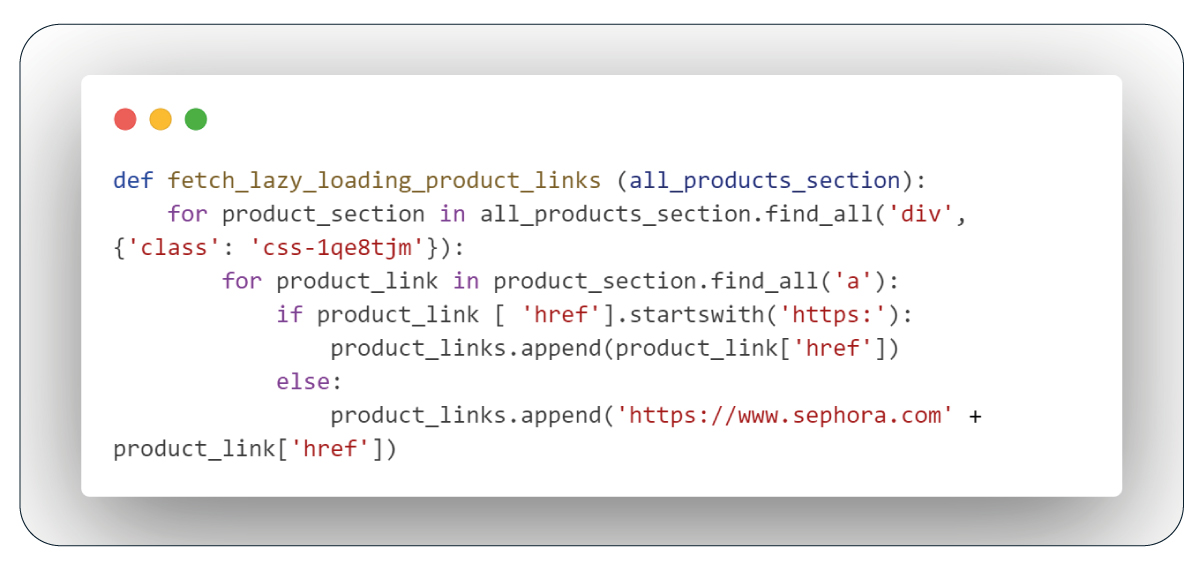
Function: Get Lazy Loading Product Links
When dealing with products featuring lazy loading, the class name is distinct, marked as 'css-1qe8tjm'. However, the process remains identical to the previous one: we locate these elements, extract the href attributes from the anchor tags, and compile the links for further use.
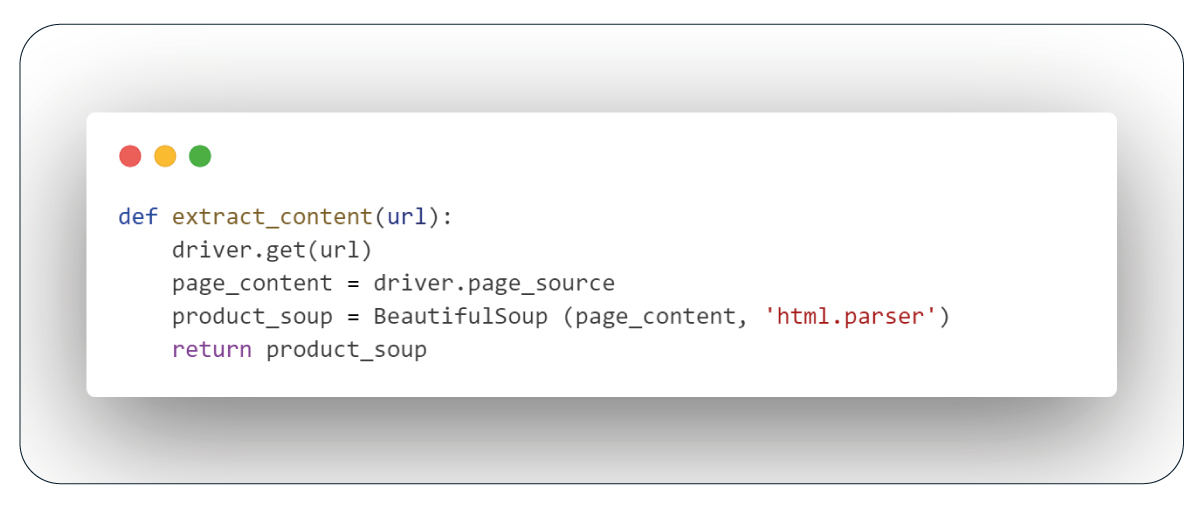
Function: Extract Page Content
This function retrieves the source code of the current web page using Selenium and parses it with BeautifulSoup, employing the 'html.parser' module for HTML code analysis.
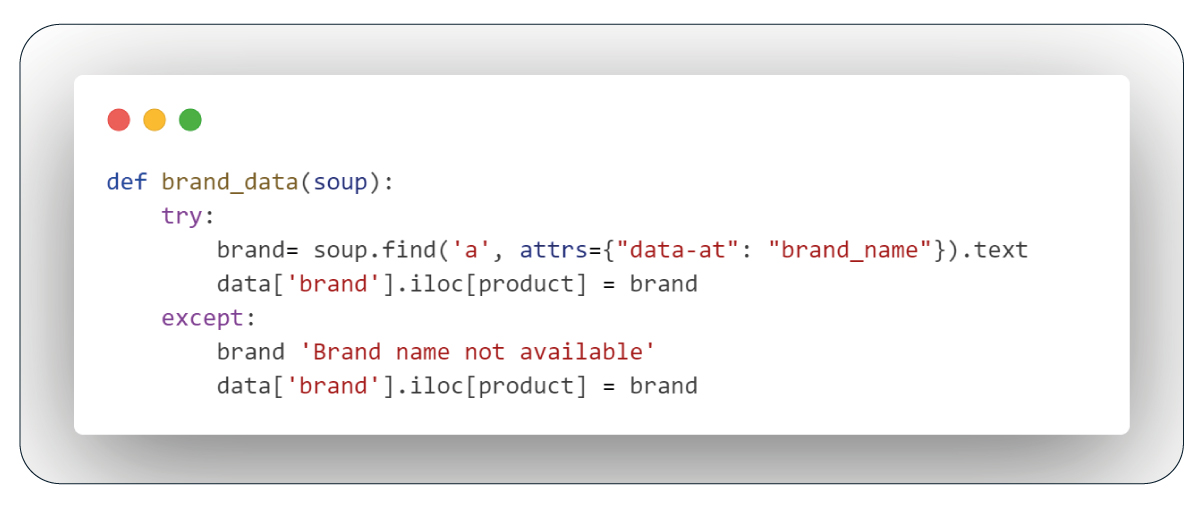
Function: Extract Brand Data
The function utilizes BeautifulSoup to locate the element with a specific attribute, like "data-at='brand_name'," and extracts the corresponding text, populating the 'brand' column. If the element isn't available, it fills the column with a default value, such as "Brand name not available."
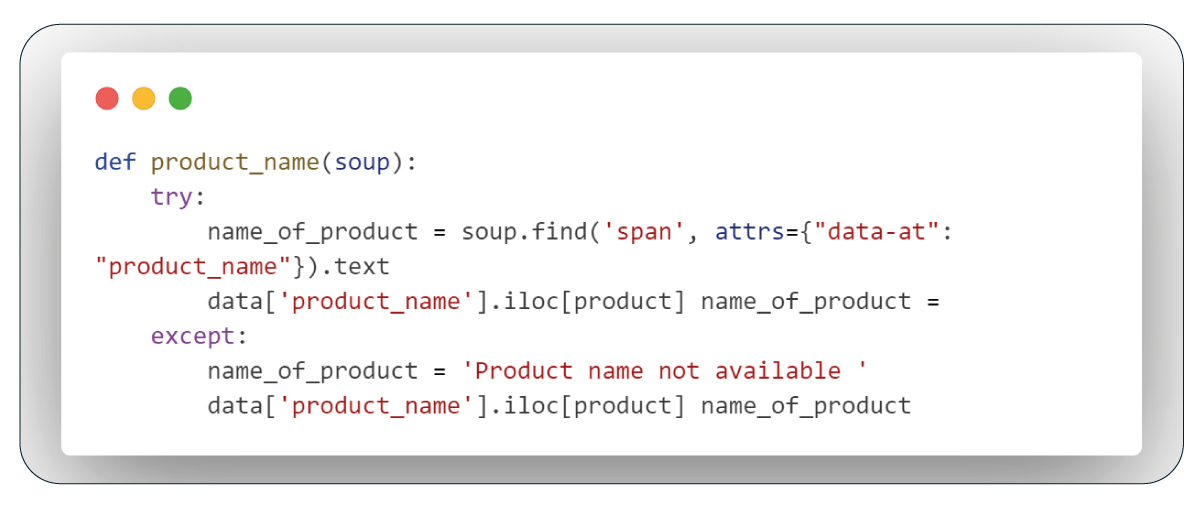
Function: Extract Product Name
This function targets the span tag with the 'data-at' attribute set to 'product_name' and extracts the text, which is in the 'product_name' column. If no text is available, it assigns "Product name not available" as the default value.
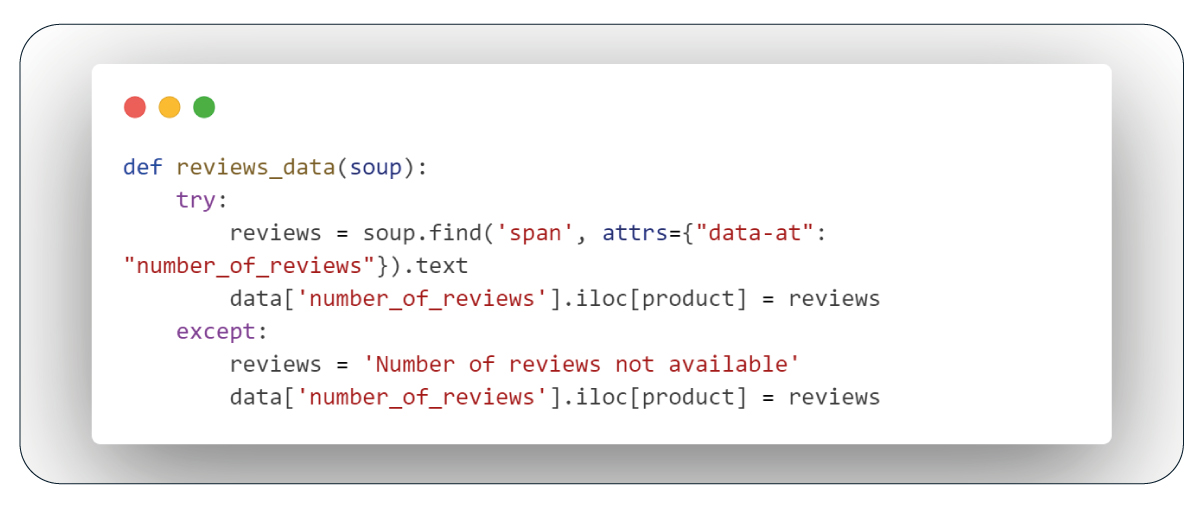
The "reviews_data" function counts the number of reviews for each product by looking for the "number_of_review" attribute in a span tag. If the attribute is available, it returns the number of reviews, and if not, it returns "Number of reviews not found."
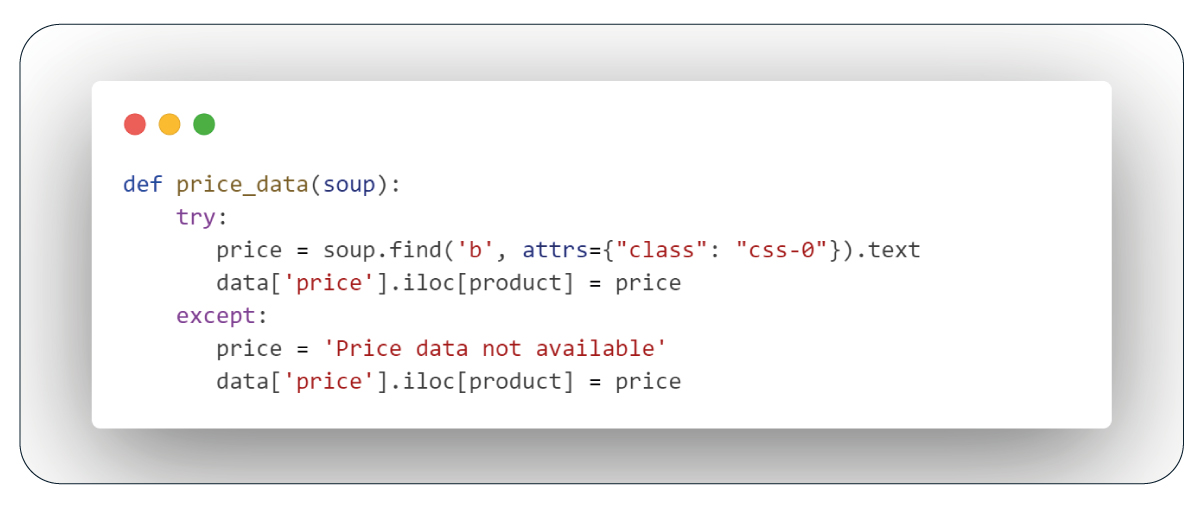
The "price_data" function retrieves the price of a product from a bold tag with the class name "ss-0." If the price is available, it returns the price; otherwise, it returns "Price data not available.
The "lipstick_ingredients" function works like the previous one. It checks for the words "Lipstick Ingredients" and a colon. If it finds them, it gets the ingredients list. If not, it says "lipstick ingredients not available."
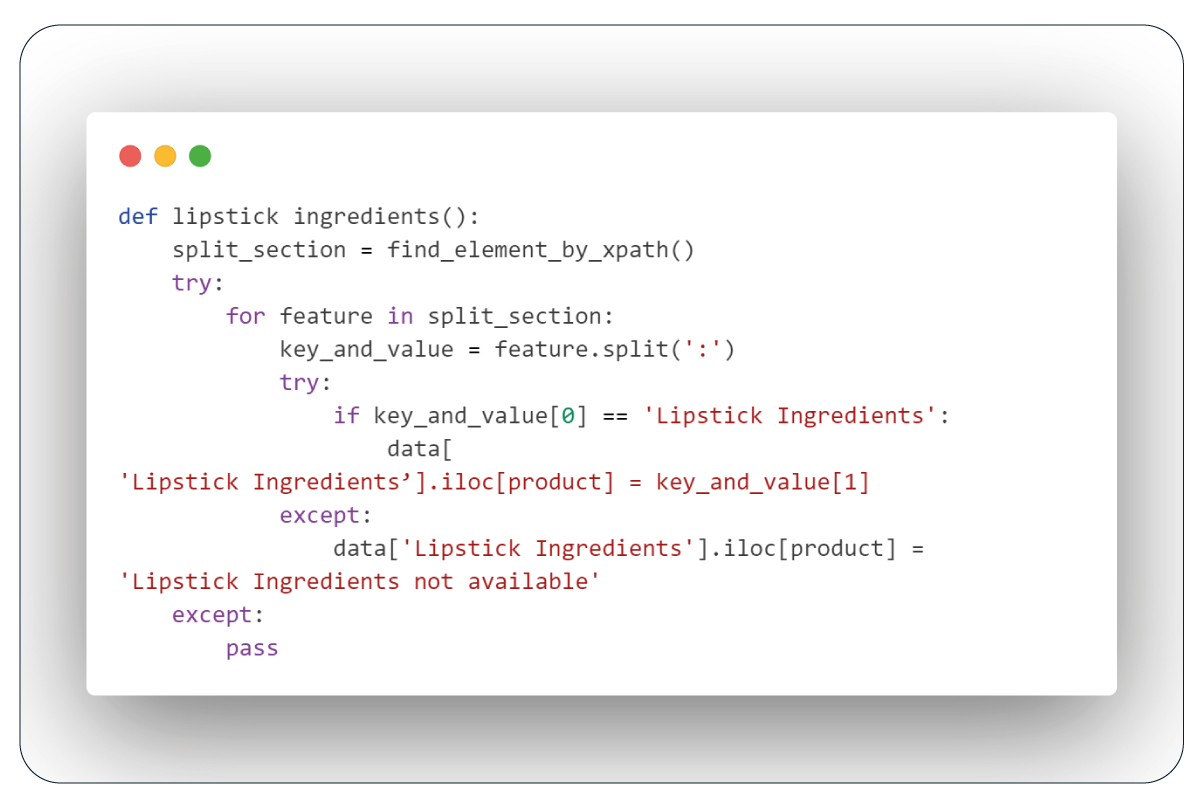
Retrieving Product URLs
To initiate the scraping process, we'll start with the homepage link using Selenium's webdriver. We'll load all available products using the pagination function, which includes handling lazy loading via the lazy_loading function. Then, we'll extract the source code of the current webpage, which now contains all available products, using BeautifulSoup with the html.parser module. We'll call the functions fetch_product_links and fetch_lazy_loading_product_links to gather links to all the products, storing them in a list named "product_links.
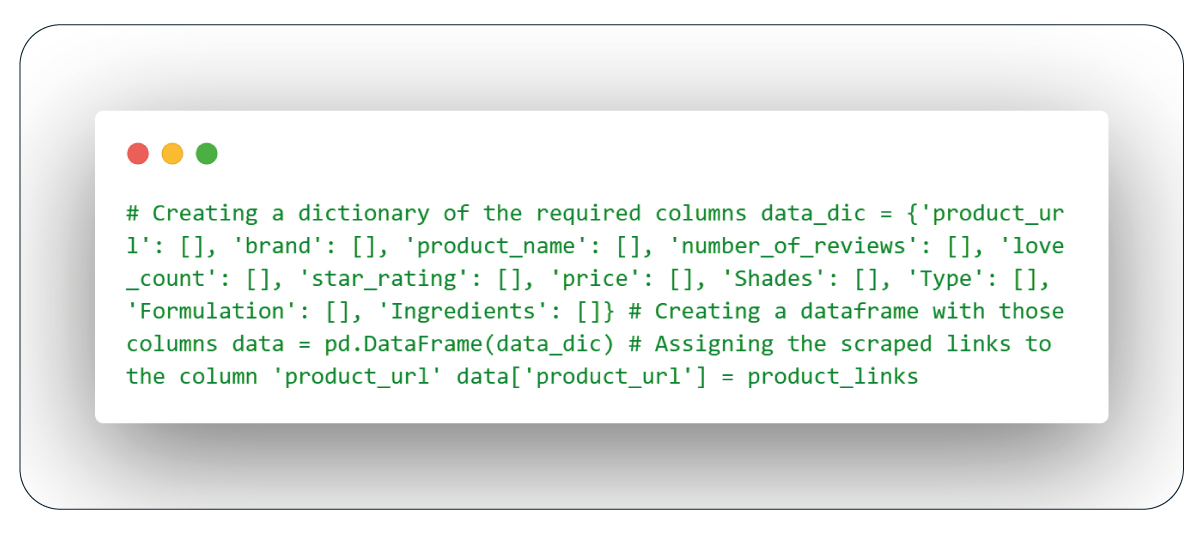
Creating a DataFrame: Initialization
To efficiently manage the data we gather, we can build a dictionary with the necessary columns as keys and empty lists as values. Subsequently, we can transform this dictionary into a Pandas DataFrame named 'data.' Lastly, we can associate the 'product_links' list with the 'product_url' column within the DataFrame. This approach simplifies the storage and organization of the collected data.
Identifying Essential Features for Extraction
Content is extracted from each 'product_url' link using the 'extract_content' function, followed by sequential calls to functions for required detail extraction."

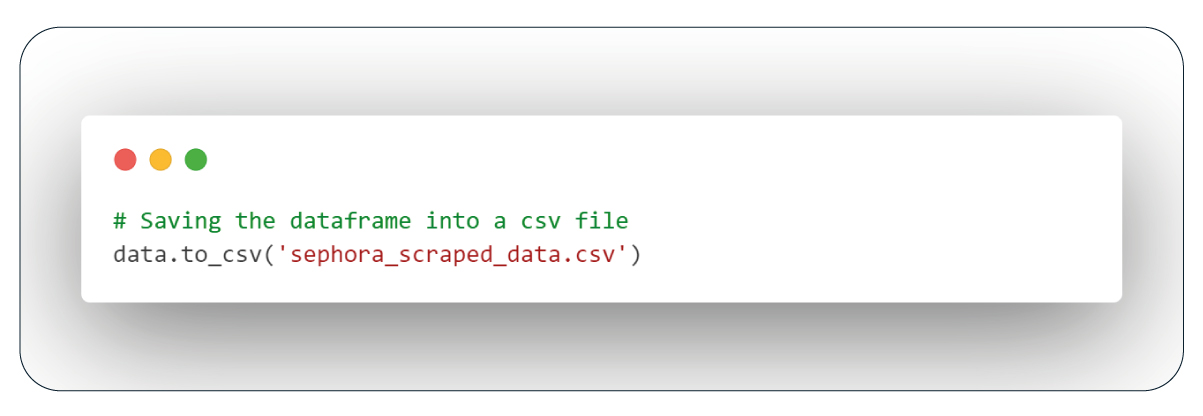
Storing Data in a CSV File
We must save the current data frame into a CSV file for future reference.
Conclusion: Web scraping is a valuable tool for data collection, but it must be done ethically and within legal boundaries. This blog showcased how we automated the data collection of lipsticks from Sephora using Python, leveraging Selenium and BeautifulSoup. BeautifulSoup is faster, while Selenium is helpful for HTML rendering. The collected data can serve various purposes, like product and brand comparisons.
At Product Data Scrape, our commitment to unwavering ethical standards permeates every aspect of our business operations, whether our Competitor Price Monitoring Services or Mobile App Data Scraping. With a global presence spanning multiple locations, we unwaveringly deliver exceptional and transparent services to meet the diverse needs of our valued clients.



































.webp)





