Web scraping has become indispensable in today's data-driven world, empowering businesses and individuals to collect and analyze information for success. By collecting valuable data from websites, eCommerce website data scraping services provides crucial insights, a competitive edge, and informed decision-making capabilities.
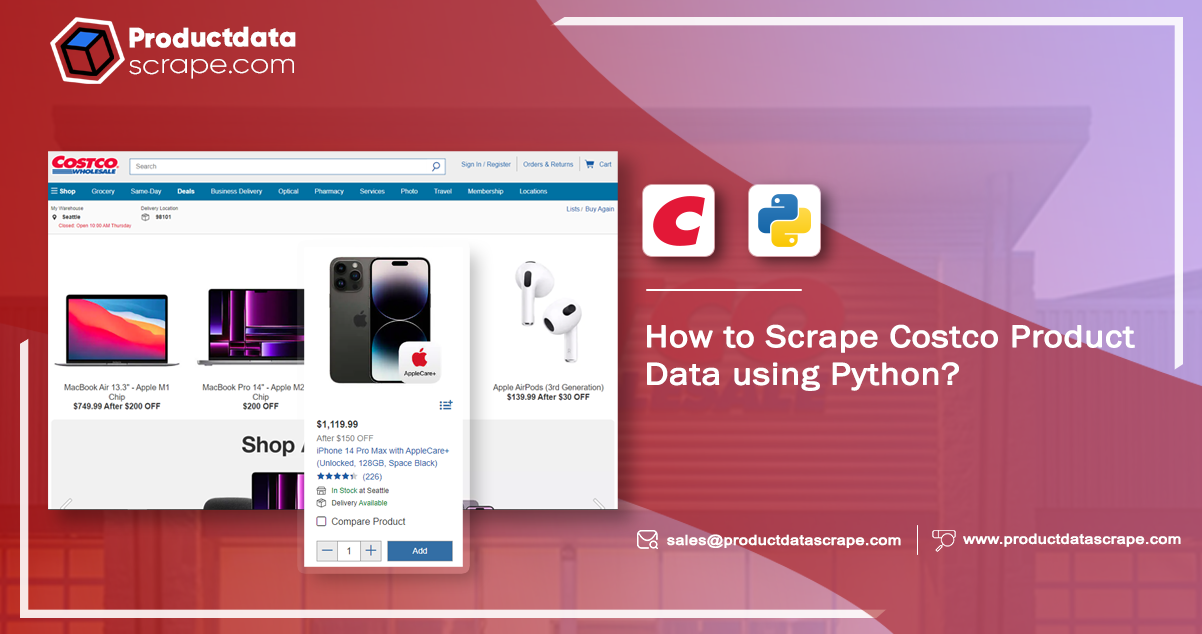
About Costco
Costco is a well-known membership-based warehouse club that offers a wide range
of products at discounted prices. It operates in several countries and is known for its
bulk-buying approach, allowing customers to purchase more oversized items at lower per-unit
costs.
This blog post will explore how Python leverages for web scraping to extract
Costco product data. We will focus on the "Electronics" category, precisely honing in on the
"Audio/Video" subcategory. The primary objective is to retrieve essential details for each
electronic device, including the product name, brand, color, item ID, category, connection type,
price, model, and description.
Throughout the post, we will delve into the process of utilizing Python's
capabilities for web scraping, highlighting essential techniques and strategies. By the end,
readers will have a comprehensive understanding of how to harness the power of web scraping
using Python to gather crucial product information from Costco's website in electronics.
List of Data Fields
- Product URL
- Product Name
- Brand
- Color
- Item Id
- Category
- Connection Type
- Price
- Model
- Description
Costco Product Data Scraping
We must first install the required libraries and dependencies to begin the
Costco data scraping process. We will be using Python as our programming language and two
popular web scraping libraries: Beautiful Soup and Selenium. Beautiful Soup parses HTML & XML
documents, while Selenium automates the process of web scraping and testing.
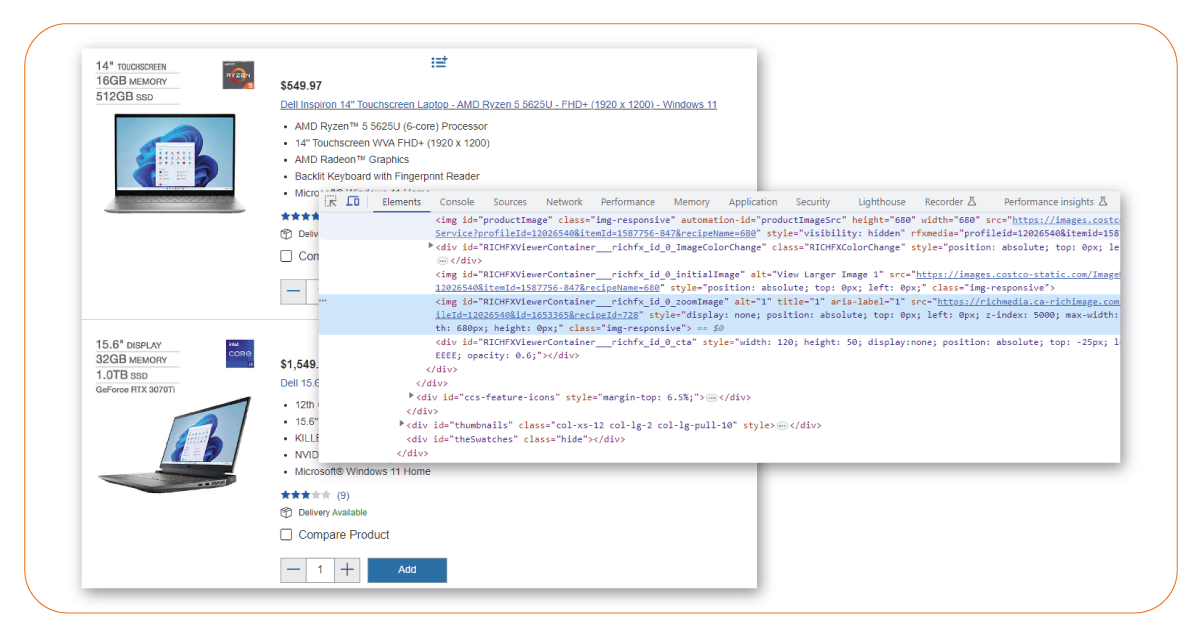
After installing the necessary libraries, we will inspect the website's
structure to identify the specific elements we want to extract. It involves analyzing the
website's HTML code and identifying the relevant tags and attributes that contain the desired
data.
After gathering this information, we will start writing our Python code for web scraping retail websites data. Our script will utilize Beautiful Soup to extract the data and Selenium to automate the necessary browser actions for scraping the website effectively. We will implement the logic to navigate the web pages, locate the desired elements, and extract the required data.
Once the scraping script is complete, we can execute it and store the extracted
data in a suitable format for analysis, such as a CSV file. Costco data scraper will allow us to
conveniently work with the scraped data and perform further processing or analysis as needed.
Instal required packages to scrape Costco product data using Python

Pandas:
Pandas is a library in Python used for data manipulation and analysis. It provides robust data
structures, such as DataFrame, suitable for organizing and manipulating structured data. Pandas
allow you to convert data from various formats into a DataFrame, perform data operations, and
save the data in different file formats, including CSV.
lxml: lxml is a library for processing XML and HTML documents. It provides
efficient and easy-to-use tools for parsing and manipulating the content of web pages. In web
scraping Costco data, lxml is commonly used with ElementTree (et) module to navigate and search
the tree-like structure of HTML or XML documents.
BeautifulSoup: BeautifulSoup is a Python library used for web scraping. It
simplifies extracting data from HTML or XML content by providing an intuitive API to navigate
and parse the document. BeautifulSoup can locate specific elements, extract their contents, and
perform other data extraction tasks.
Selenium: Selenium is a library that enables the automation of web browsers. It
allows you to control web browsers programmatically, interact with website elements, pretend
user actions, and extract Costco data from web pages. Selenium is helpful for web scraping tasks
that require interacting with JavaScript-driven websites or websites with complex user
interactions.
Webdriver: Webdriver is a package Selenium uses to interact with web browsers. It serves as a bridge between Selenium and the browser, enabling communication and control. Webdriver provides different implementations for various web browsers, allowing Selenium to automate actions and scrape data from e-commerce websites.
driver= webdriver.firefox()
When using Selenium, one crucial step is creating an instance of a web driver. A web driver class
facilitates interaction with a specific web browser, such as Chrome, Firefox, or Edge. In the
following code snippet, we create an instance of the Chrome web driver using Webdriver.Chrome().
This line of code allows us to control the Chrome browser and simulate user interactions with
web pages.
Utilizing the web driver allows us to navigate through different pages, interact with elements on
the page, fill out forms, click buttons, and extract the required information. This powerful
tool enables us to automate tasks and efficiently gather data. With Selenium and web drivers,
you can fully harness the potential of web scraping and automate your data collection process
proficiently.
By leveraging the flexibility and functionality of Selenium and web drivers and Costco product data scraping services, you can streamline your web scraping workflow and achieve more effective and accurate data extraction.
Understanding the Web Scraping Functions
Now that we have a solid understanding of web scraping and the tools we'll use let's
dive into the code. We'll look closer at the functions defined for the web scraping process.
Functions provide several benefits, including organization, reusability, and maintenance, making
it easier to understand, debug, and update the codebase.
By structuring the code into functions, we improve its modularity, making it easier
to manage and maintain. Each function encapsulates a specific task, allowing us to reuse them
throughout the codebase. This approach enhances code readability and efficiency by focusing on
individual components of the scraping process.

This function locates the link for the "Audio/Video" category on the Costco
electronics website using the find_element() method with By.XPATH. Once the link is available,
the function uses the click() method to simulate a user click and navigate to the corresponding
page. This functionality enables us to access the desired category page and extract the relevant
data.
Function to Extract Category Links:

After navigating to the Audio/Video category, this function extracts the links of
the four subcategories displayed. It enables further scraping on those specific pages. The XPath
() method of the DOM object helps locate all elements that match the provided XPath expression.
In this case, the XPath expression selects all the "href" attributes of the "a" elements that
are descendants of elements with the class "categoryclist_v2".

Function to Extract Product Links
Once we have obtained the links to the subcategories under the Audio/Video category,
we can scrape all the links of the products present within these categories.
This function utilizes the previously defined category_links() and extract_content()
functions to navigate to each subcategory page and extract the links of all the products within
each subcategory.
The function employs the XPath () method of the content object. It selects all the
product links based on a specified XPath expression. In this case, the XPath expression targets
the "href" attributes of the "a" elements that are descendants of elements with the
automation-id "productList" and have an "href" attribute ending with ".html."
Function to Extract Product Brand

Function to Extract Product Price

In this function, the XPath () method of the DOM object helps select the element's text
with the automation-id "productPriceOutput." If the price is available, it is extracted and assigned
to the "price" column. However, if the price is unavailable, the function assigns the "Price is not
available" to the "price" column.
Function to Extract Product Item Id

Function to Extract Product Description

Function to Extract Product Model
In this function, the XPath () method of the DOM object is to select the element's
text with the id "model-no."

Function to Extract Product Connection Type
Function to Extract Product Category

In this function, the XPath () method of the DOM object is used to select the text
of the
10th element with the itemprop attribute set to "name." It allows us to extract the product
category
information.
Function to Extract Product Color

Start the Scraping Process
We will start the scraping process by calling each previously defined function to
retrieve the
desired data.

The first step involves utilizing the webdriver to navigate to the Costco electronic
categories page
using the provided URL. We will then employ the click_url() function to click on the Audio/Video
category and
extract the HTML content of the page.

To store the scraped data, we will create a dictionary with the required columns,
including
'product_url,' 'item_id,' 'brand,' 'product_name,' 'color,' 'model,' 'price,' 'connection_type,'
'category,' and
'description.'

The script now invokes the product_links function, which extracts the links of all
the products
present within the four subcategories of the Audio/Video category.

The script iterates through each product in this code snippet's 'data' data frame.
It retrieves the product URL from the 'product_url' column and uses the extract_content()
function to obtain the HTML content of the corresponding product page. The previously defined
functions extract specific features such as model, brand, connection type, price, color, item
ID, category, description, and product name.
data.to_csv('cstco_data.csv')
Conclusion: Throughout this tutorial, we have acquired the skills
to utilize Python and its web scraping libraries to extract valuable product information from
Costco's website. Our focus was primarily on the "Audio/Video" subcategory within the broader
"Electronics" category. We comprehensively explored the process of inspecting the website
structure, identifying the relevant elements for extraction, and implementing Python code to
automate the scraping procedure.
At Product Data Scrape, we ensure that our Competitor
Price Monitoring Services and Mobile App Data Scraping maintain the highest standards of
business ethics and lead all operations. We have multiple offices around the world to fulfill
our
customers' requirements.








.webp "thumb")
.webp "thumb")
.webp "thumb")

























.webp)





