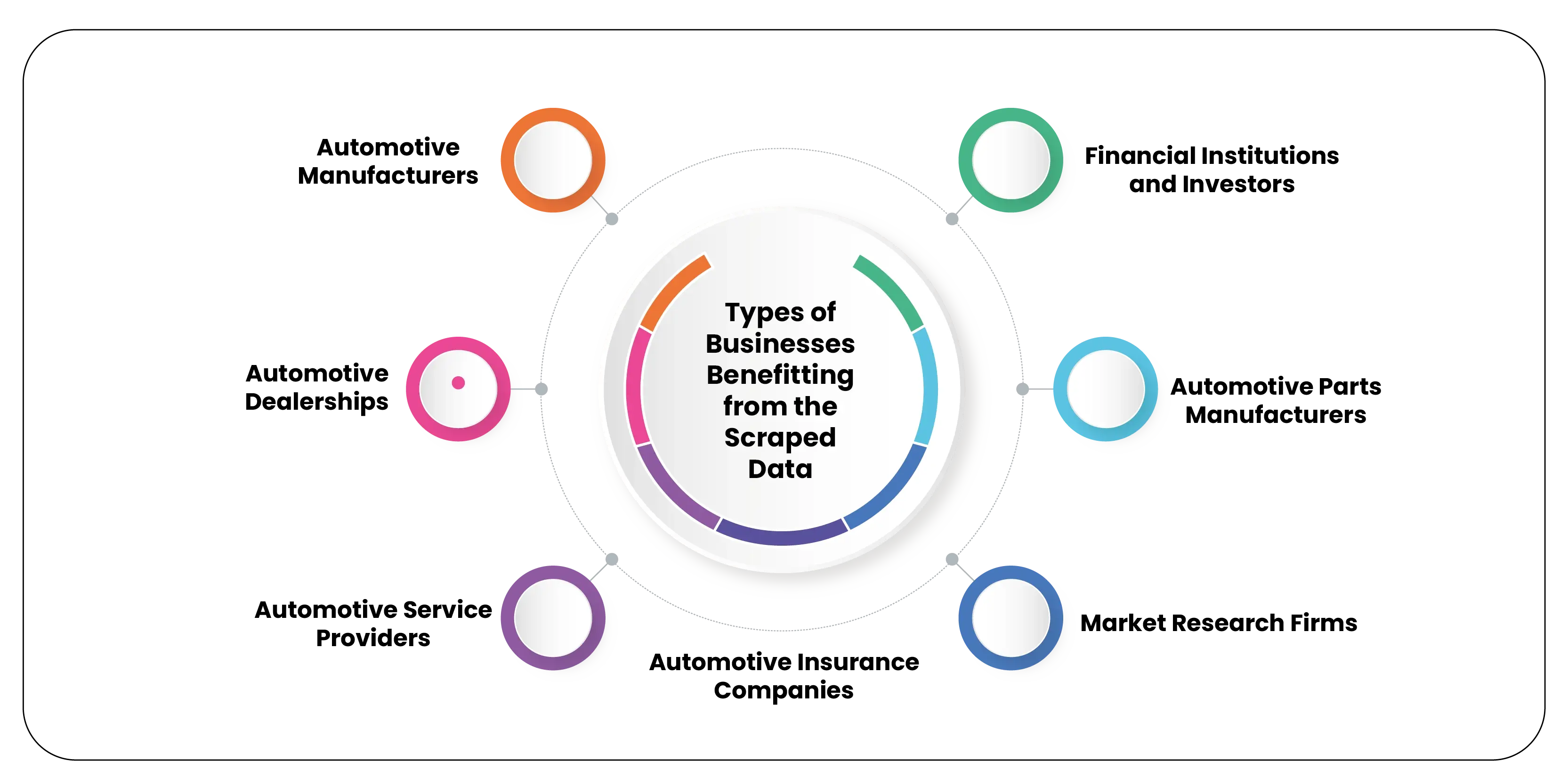
Overall, scraped data from Chinese vehicle websites has broad applicability across industries, enabling businesses to gain insights, make informed decisions, and stay competitive in the dynamic automotive market.
Steps to Scrape Vehicle Specifications from Chinese Website

Following are the steps to scrape vehicle specifications from Chinese websites:
Starting Point:
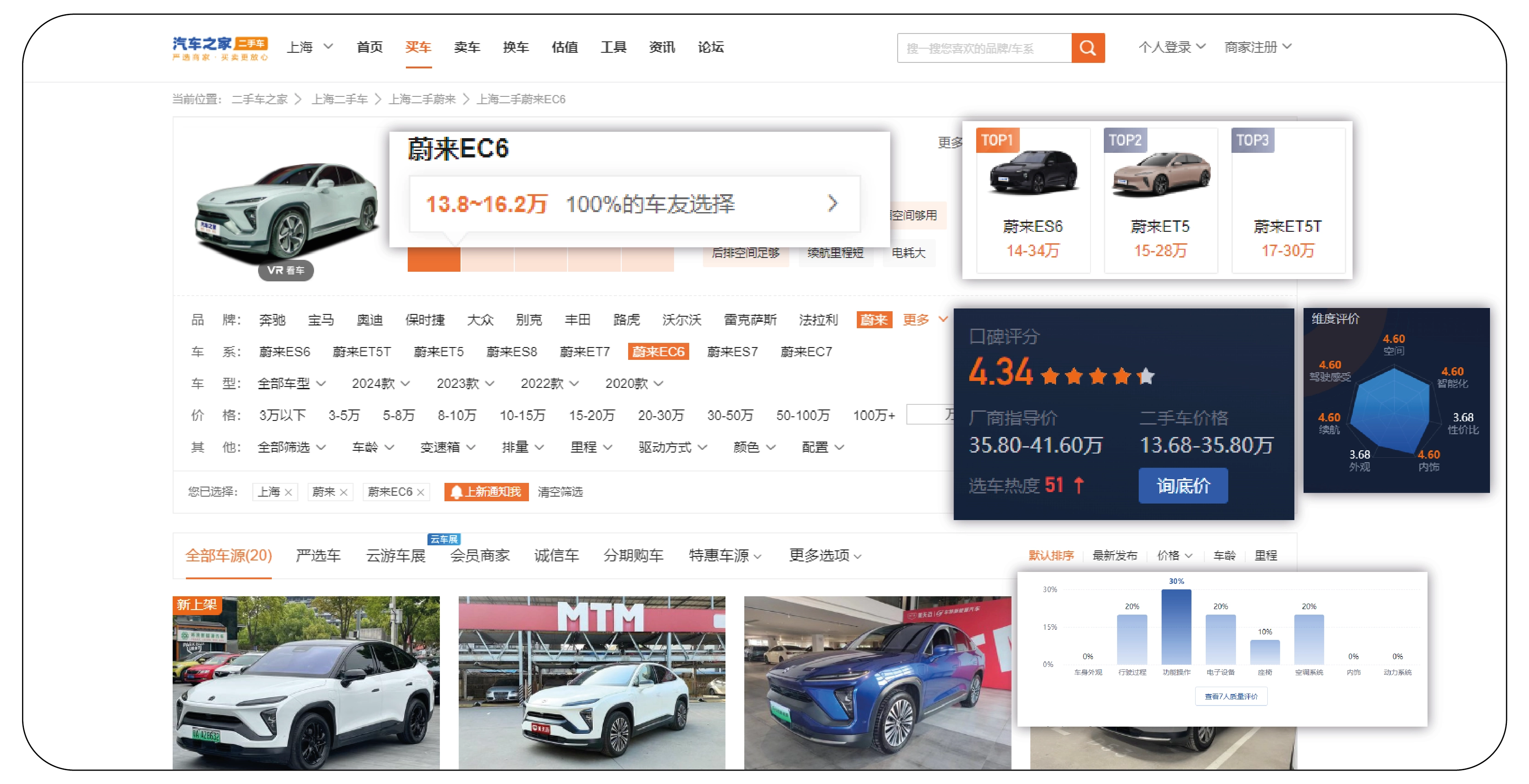
We kickstart our data scraping journey by navigating to the website's search page: car.autohome.com.cn/searchcar. Here, we encounter a wealth of information regarding the extensive array of vehicle models available, totaling an impressive 1132 models and 8526 vehicles.
import requests
from bs4 import BeautifulSoup
# Navigate to the search page
url = "https://car.autohome.com.cn/searchcar"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extract information about vehicle models
vehicle_models = soup.find_all("div", class_="list-cont")
# Total number of models and vehicles
total_models = len(vehicle_models)
total_vehicles = sum(len(model.find_all("li")) for model in vehicle_models)
Individual Vehicle Pages:
Each vehicle model on the search page corresponds to its unique individual page. For instance, the page for model 5569 can be accessed at: www.autohome.com.cn/5569/. This page serves as a gateway to the detailed specification page and provides basic information about the model.
# Extract links to individual vehicle pages
vehicle_links = []
for model in vehicle_models:
links = model.find_all("li")
for link in links:
vehicle_link = link.find("a")["href"]
vehicle_links.append(vehicle_link)
# Access individual vehicle pages
vehicle_pages = []
for link in vehicle_links:
response = requests.get(link)
vehicle_pages.append(response.text)
Detailed Specification Page:
The crux of our endeavor lies in extracting data from the detailed specification page for each vehicle model. This page offers comprehensive insights into the model's attributes and variants. We access the detailed specification page by appending the model number to the URL, e.g., car.autohome.com.cn/config/series/5569.html. Here, we meticulously extract the vehicle attributes and variants, which will be compiled into our Excel file.
# Extract detailed specification page URLs
detailed_spec_pages = []
for page in vehicle_pages:
soup = BeautifulSoup(page, 'html.parser')
model_number = soup.find("span", class_="pl").text.strip()
detailed_spec_url = f"https://car.autohome.com.cn/config/series/{model_number}.html"
detailed_spec_pages.append(detailed_spec_url)
# Extract data from detailed specification pages
vehicle_attributes = []
for url in detailed_spec_pages:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Extract vehicle attributes
attributes = soup.find_all("div", class_="config-data")
vehicle_attributes.append(attributes)
End Result:
After successfully executing our scraping script, we are rewarded with an Excel file brimming with meticulously organized vehicle specifications. Each row corresponds to a specific vehicle model, while the columns represent various attributes such as engine type, transmission, dimensions, and features. Notably, when a particular vehicle specification page lacks a specific attribute present in others, the corresponding cell in the Excel file remains blank, ensuring data integrity and consistency.
# Compile data into Excel file
import pandas as pd
# Create DataFrame to store vehicle specifications
df = pd.DataFrame(columns=['Model', 'Engine Type', 'Transmission', 'Dimensions', 'Features'])
# Populate DataFrame with scraped data
for attributes in vehicle_attributes:
model_specs = {}
for attribute in attributes:
# Extract specific attributes (modify as needed)
model_specs['Model'] = attribute.find("h3", class_="config-name").text.strip()
model_specs['Engine Type'] = attribute.find("div", class_="param-name", text="Engine Type").find_next_sibling("div").text.strip()
model_specs['Transmission'] = attribute.find("div", class_="param-name", text="Transmission").find_next_sibling("div").text.strip()
model_specs['Dimensions'] = attribute.find("div", class_="param-name", text="Dimensions").find_next_sibling("div").text.strip()
model_specs['Features'] = attribute.find("div", class_="param-name", text="Features").find_next_sibling("div").text.strip()
df = df.append(model_specs, ignore_index=True)
# Save DataFrame to Excel file
df.to_excel("vehicle_specifications.xlsx", index=False)
Conclusion: In conclusion, implementing a data scraping script enables us to efficiently extract detailed vehicle specifications from the expansive Chinese car database website, car.autohome.com.cn. This data serves as a veritable treasure trove for consumers, manufacturers, and researchers, empowering them to make informed decisions and gain invaluable insights into the automotive landscape. With the Excel file containing all specifications meticulously organized, users can seamlessly analyze and compare different vehicle models, facilitating better decision-making processes and driving progress in the ever-evolving automotive industry.
At Product Data Scrape, ethical principles guide our operations. From Competitor Price Monitoring to Mobile App Data Scraping, transparency and integrity define our approach. With offices in various locations, we provide tailored solutions, aiming to exceed client expectations and drive success in data analytics.




































.webp)





