
In today's digital era, the internet is an immense repository of valuable information, from e-
commerce platforms to social media sites. This vast sea of data offers significant potential
for businesses across various industries. However, companies must extract and categorize
this data effectively to harness its power. This process, known as Online Website Data
Scraping and Categorization, is crucial for industries like market research and e-commerce.
By implementing Web Scraping and Data Categorization, businesses can transform
unstructured data into actionable insights, driving decisions such as Price Monitoring and
refining their Pricing Strategy. With the right approach, data scraping and categorization enable companies to stay competitive, respond to market trends, and optimize their
operations. This powerful combination allows businesses to make informed decisions,
ensuring they remain ahead in the ever-evolving digital landscape.
What is Online Website Data Scraping?

Online Website Data Extraction and Categorization, commonly called web scraping,
involves systematically extracting data from websites. This can include various content
types, such as text, images, and videos, as well as more detailed information like pricing,
product details, customer reviews, and metadata. Unlike manual data collection, which is
often time-consuming and prone to errors, web scraping automates the process, allowing
for large-scale data extraction with minimal effort.
Web Scraping Retail Websites Data is a crucial application of this technology, enabling businesses to gather and analyze information from multiple online stores efficiently. Tools
used for this purpose, often known as "scrapers" or "bots," are designed to navigate
websites, access specific pages, and Extract Website Content Extraction and Categorization
based on predefined rules. These tools are invaluable for various tasks, including price
comparison, competitor analysis, and market trend monitoring.
The Importance of Data Scraping

Data scraping offers numerous advantages for businesses and organizations seeking a
competitive edge. Here's a detailed look at its key benefits:
1. Market Research: Companies can gather and analyze valuable market insights by
leveraging the automatic collection of data from public websites. This includes
tracking market trends, understanding customer preferences, and evaluating
competitor strategies. Such detailed analysis is essential for making well-informed
business decisions and adapting to market changes effectively.
2. E-commerce: Online retailers benefit significantly from data scraping. Using a
Webpage Data Collection Service to extract product data from competitors'
websites, including prices and stock levels, they can fine-tune their pricing strategies
and manage inventory in real time. This dynamic approach helps them stay
competitive and optimize sales.
3. Lead Generation: Businesses can utilize data scraping to gather contact information
from various sources such as directories and social media profiles. This Online
Website Information Data Extraction enables the creation of targeted lead lists for
marketing campaigns, increasing the effectiveness of their outreach efforts and
improving lead conversion rates.
4. Content Aggregation: Media outlets and creators can use E-Commerce Data
Collection Services to scrape relevant news articles, blog posts, and social media
updates. This helps them curate and present timely and pertinent content to their
audiences, enhancing engagement and keeping their content offerings fresh and
relevant.
5.Academic Research: Researchers can employ data scraping to support their studies
by collecting data from various websites and online databases. Whether analyzing
social behavior, economic trends, or scientific developments, data scraping uses
software code to extract data from websites efficiently, facilitating comprehensive
research and data analysis.
In summary, the strategic application of data scraping can drive better decision-making,
enhance competitive positioning, and streamline data collection processes across various
domains.
Ethical Considerations and Legal Implications
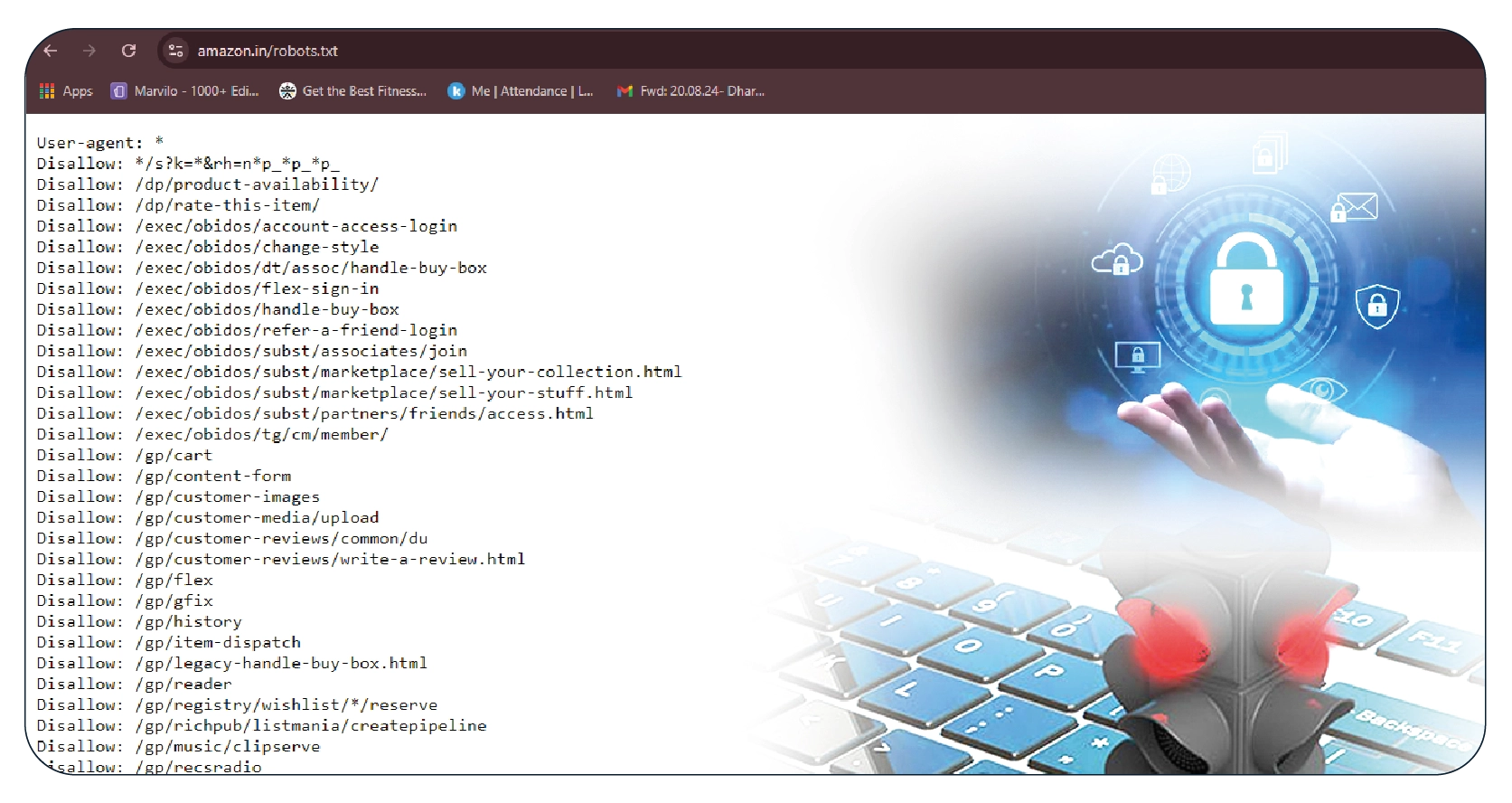
While data scraping offers numerous benefits, it's essential to consider the ethical and legal
aspects. Not all websites permit scraping, and some have terms of service that explicitly
prohibit it. Scraping a website without permission can lead to legal consequences, including
cease and desist orders, lawsuits, or even criminal charges.
To ensure ethical scraping, consider the following:
Respect Robots.txt: Many websites have a robots.txt file that specifies which parts
of the site can be scraped. Adhering to these guidelines is crucial.
Rate Limiting: Excessive scraping can overwhelm a website's servers, leading to
downtime. Implementing rate limits ensures that your scraper doesn't cause harm.
Data Privacy: If you're scraping personal data, be aware of privacy laws such as the
General Data Protection Regulation (GDPR) in the European Union. Ensure that the
data you collect is used responsibly.
The Process of Web Scraping
The process of web scraping involves several steps, each of which is crucial to extracting and
categorizing data effectively:
1. Identifying the Target Website: The first step in web scraping is identifying the
website or websites from which you want to extract data. This could be an e-
commerce site like Amazon, a news aggregator like Google News, or a social media
platform like Twitter. The choice of website depends on the type of data you need.
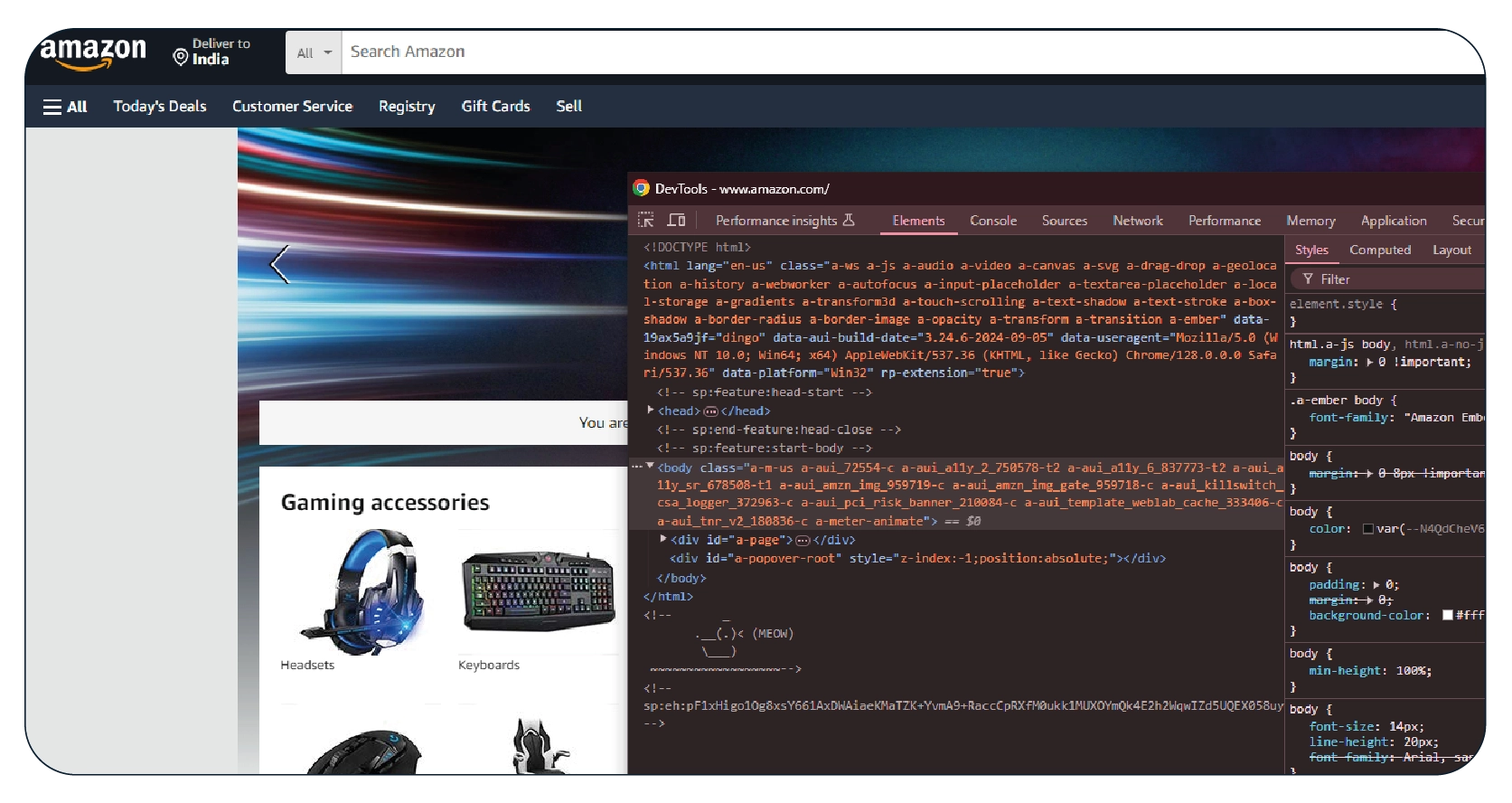
2. Analyzing the Website's Structure: Websites are typically structured using HTML
and CSS, and understanding this structure is critical to successful scraping. Tools like
browser developer consoles can help you inspect a webpage's HTML and identify the
elements you want to scrape.
3. Choosing the Right Tools: You can choose from various web scraping tools
depending on your needs and technical expertise. Some popular options include:
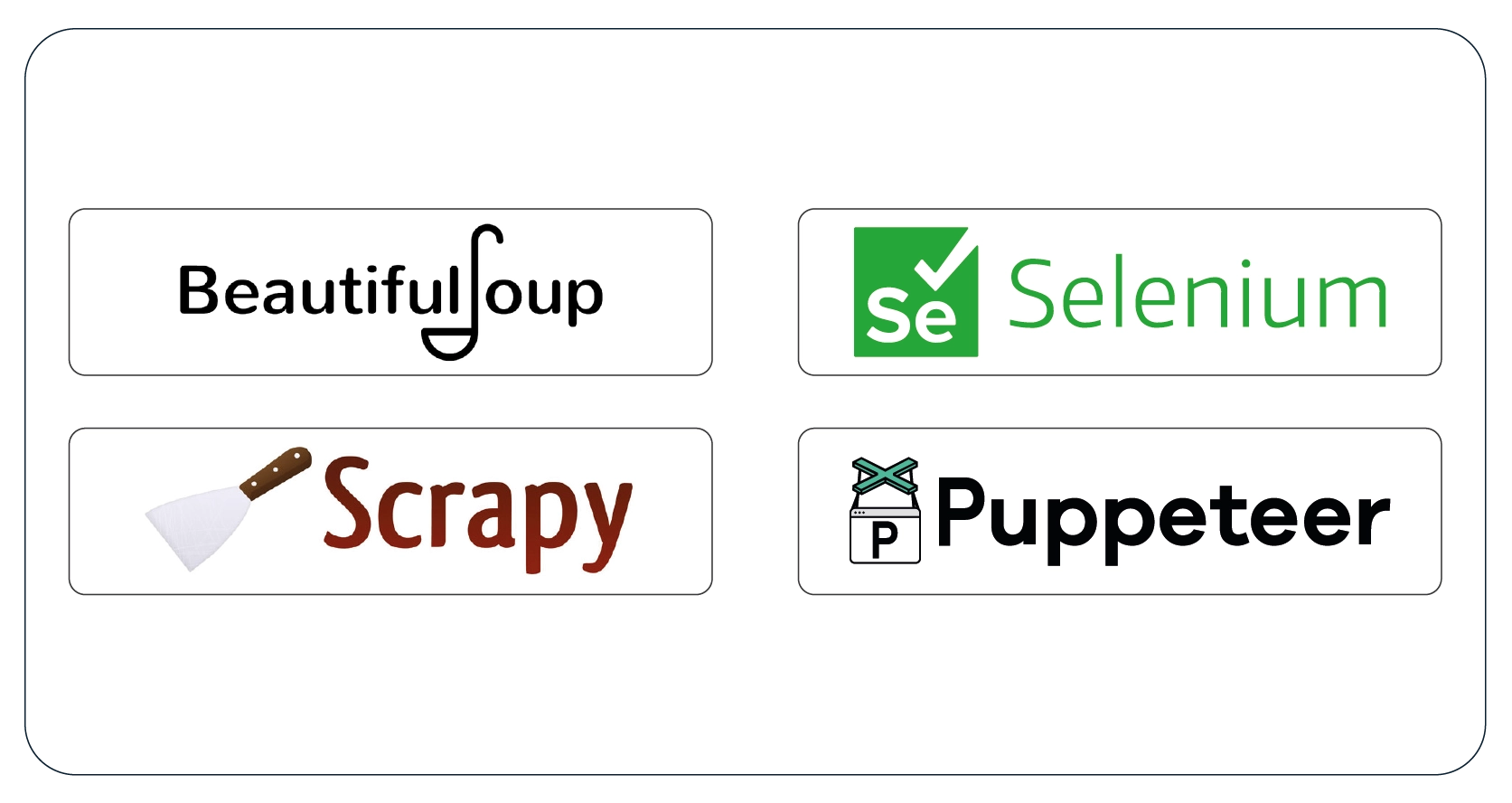
- BeautifulSoup (Python): A powerful library for parsing HTML and XML
documents. Ideal for beginners.
- Scrapy (Python): A robust web scraping framework for advanced data
extraction and processing.
- Selenium (Python/Java): A tool for automating web browsers, often used for
scraping dynamic content.
4. Extracting the Data: Once you've set up your scraper, the next step is to run it and
extract the desired data. This data is often stored in a structured format such as CSV,
JSON, or XML.
5. Data Cleaning: Raw scraped data is often messy and may contain duplicates,
irrelevant information, or errors. Data cleaning involves processing the scraped data
to remove these issues, ensuring the final dataset is accurate and reliable.

6. Data Categorization: Categorization is the process of organizing data into predefined
groups or classes. For instance, an e-commerce site might categorize scraped
product data by brand, price range, or category (e.g., electronics, clothing). Effective
categorization is crucial for making sense of large datasets and drawing meaningful
insights.
7. Data Storage: After categorizing the data, it must be stored to make it easily
accessible for analysis. Standard storage options include databases (e.g., MySQL,
MongoDB) or cloud storage solutions (e.g., AWS S3).

The Role of Categorization in Data Scraping
While data scraping focuses on extracting information, categorization is crucial for
organizing that information to make it usable. Even the most comprehensive scraped data
can be easily interpreted and analyzed with proper categorization. Categorization
transforms raw data into structured, actionable insights, facilitating various applications.
Here's how:
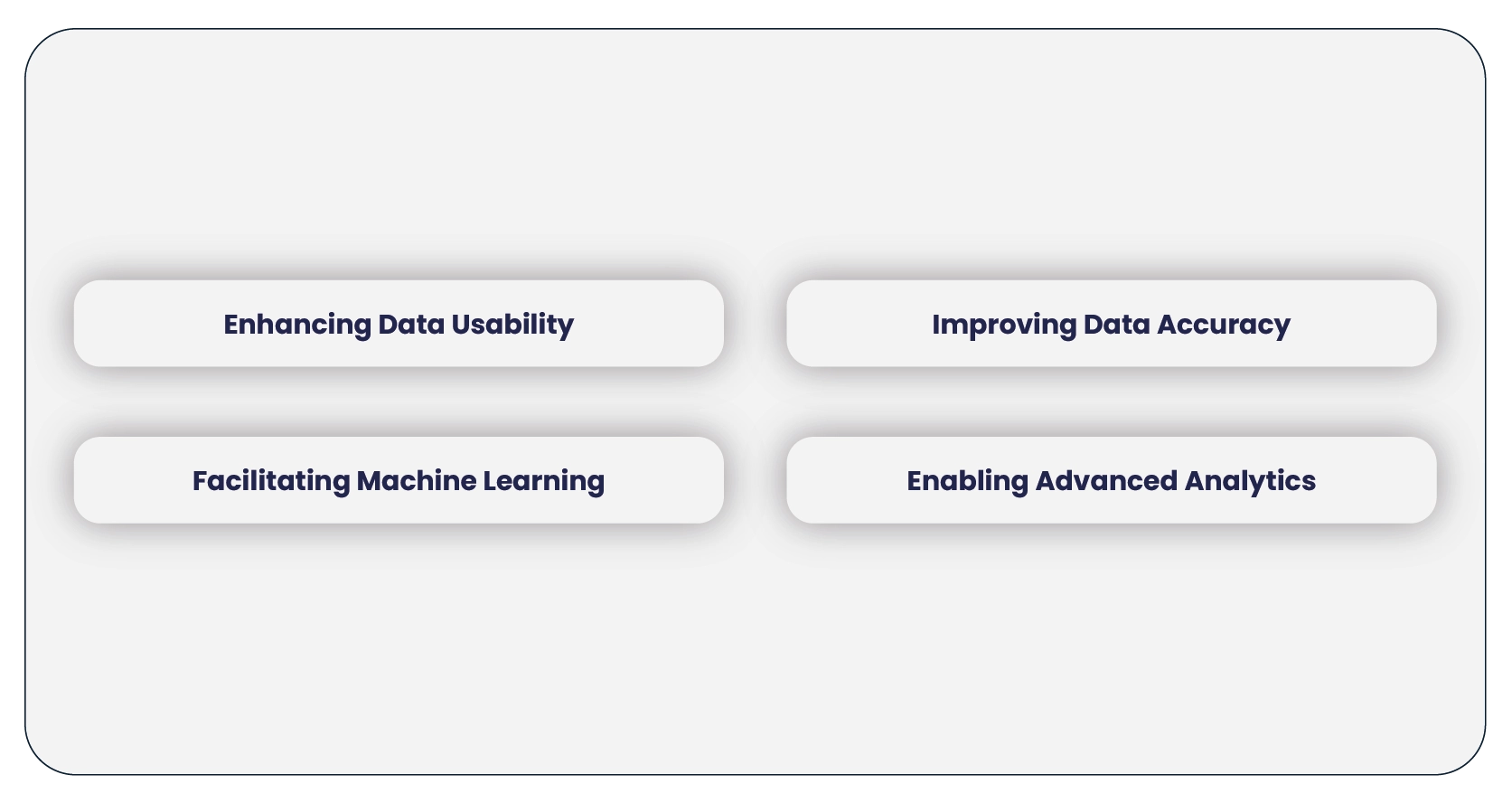
1. Enhancing Data Usability: Categorized data is significantly more straightforward to
navigate and analyze. For example, in an e-commerce setting, organizing products by
type, brand, or price range allows businesses to swiftly identify trends and make
informed decisions about inventory, pricing, and marketing strategies. This
structured approach is often achieved through Website Scraping & Categorization.
2. Improving Data Accuracy: Proper categorization reduces the risk of errors and
inconsistencies. For instance, ensuring that products are categorized under the
correct headings helps maintain the accuracy and relevance of comparisons, such as
price comparisons. This is essential for ensuring meaningful and precise insights from
the data extracted through Extract eCommerce Data Scraping Services.
3. Facilitating Machine Learning: Structured, categorized data is vital for machine
learning models that require well-organized inputs to make accurate predictions. For
example, a recommendation engine on an e-commerce site can use categorized
product data to suggest items similar to those a customer has previously viewed or
purchased. Effective website information extraction and categorized data enhance
this capability.
4. Enabling Advanced Analytics: With categorized data, businesses can perform more
sophisticated analyses, such as segmentation, trend analysis, and predictive
modeling. For example, a retailer might categorize customers based on their
purchase history and use this data to forecast future buying behaviors, thus
leveraging advanced analytics for strategic decision-making.
In summary, while data scraping extracts valuable information, categorization ensures that
this data is organized and structured for practical use, enabling better decision-making and
advanced analytical capabilities.
Challenges in Data Scraping and Categorization

While web scraping and categorization offer numerous benefits, they are not without
challenges. Some of the most common issues include:
1. Website Structure Changes:
Websites frequently update their structure, which can break existing scraping scripts. This
requires constant monitoring and updating of scrapers to ensure they continue to function
correctly.
2. Handling Dynamic Content:
Many modern websites use JavaScript to load content dynamically. This can make it difficult
to scrape data using traditional methods, as the content may be outside the initial HTML
source. Tools like Selenium can help by automating browser interactions, but they are more
complex to set up and use.
3. Dealing with Captchas and Anti-Scraping Measures:
Websites often implement measures to prevent scraping, such as Captchas, IP blocking, or
rate limiting. Overcoming these barriers requires advanced techniques like rotating IP
addresses, using proxies, or incorporating machine learning to solve Captchas.
4. Data Quality Issues:
Scraped data is often incomplete, inconsistent, or noisy. Ensuring data quality requires
rigorous data cleaning and validation processes.
5. Legal and Ethical Concerns:
As mentioned earlier, scraping can raise legal and ethical issues, particularly involving
copyrighted content, personal data, or proprietary information. Navigating these concerns
requires careful consideration and adherence to relevant laws and guidelines.
Best Practices for Effective Web Scraping and Categorization

To maximize the benefits of web scraping and categorization, it's essential to follow the best
practices:
1. Start Small and Scale Gradually:
Begin by scraping a small subset of data to test your approach. Once confident in your
methods, you can scale up to larger datasets.
2. Use Proxies and Rotate IPs:
To avoid getting blocked by websites, use proxies to rotate your IP address periodically. This
helps distribute the load and reduces the risk of detection.
3. Respect Website Policies:
Always check the robots.txt file and the website's terms of service before scraping. Respect
any restrictions and consider seeking permission if necessary.
4. Automate Where Possible:
Use automation tools and scripts to streamline the scraping and categorization process. This
not only saves time but also reduces the likelihood of errors.
5. Document Your Process:
Keep detailed records of your scraping process, including the tools used, settings configured,
and data extracted. This documentation is invaluable for troubleshooting and future
reference.
6. Stay Updated on Legal Requirements:
Laws and regulations related to data scraping are constantly evolving. Stay informed about
relevant legal requirements, especially if scraping sensitive or personal data.
7. Validate and Clean Data:
Validate your data against known standards or benchmarks to ensure its quality. Clean the
data to remove duplicates, inconsistencies, and errors before categorizing it.
8. Categorize Thoughtfully:
Choose categories that are meaningful and relevant to your analysis. Avoid over-
categorization, which can make the data difficult to navigate and analyze.
Conclusion
Online website data scraping and categorization are potent tools for unlocking the
potential of the vast amounts of information available on the web. By automating the
extraction and organization of data, businesses can gain valuable insights that drive
informed decision-making, enhance customer experiences, and foster innovation. However,
with great power comes great responsibility. Ethical considerations, legal compliance, and
technical challenges must all be carefully managed to ensure that the benefits of data
scraping are realized without causing harm. By following best practices and staying informed
about the latest developments in the field, organizations can leverage data scraping and
categorization to their full potential, gaining a competitive edge in the ever-evolving digital
landscape.
At Product Data Scrape, we strongly emphasize ethical practices across all our services, including Competitor Price Monitoring and Mobile App Data Scraping. Our commitment to transparency and integrity is at the heart of everything we do. With a global presence and a
focus on personalized solutions, we aim to exceed client expectations and drive success in
data analytics. Our dedication to ethical principles ensures that our operations are both
responsible and effective.



































.webp)





