
E-commerce has revolutionized buying and selling goods, services, and digital
products. It has become an integral part of our daily lives, enabling us to make purchases,
register for services, and easily access digital content. "e-commerce" refers to the online sale
of goods or services involving the electronic transfer of funds and data between parties.
Over the years, e-commerce has experienced significant advancements since its
early days of electronic data interchange and the emergence of online shopping. Today, it
thrives due to technological developments and the widespread use of smartphones. The convenience
of shopping from anywhere at any time has propelled the growth of e-commerce. Hence, with the
rising demand for online shopping, eCommerce data scraping has also increased.
About eCommerce Website
E-commerce websites serve as virtual marketplaces where individuals and
businesses can buy and sell. Comparable to traditional physical retail stores, these online
platforms facilitate transactions between buyers and sellers. However, the critical distinction
is that e-commerce transactions occur exclusively over the Internet, eliminating the need for a
physical store location.
List of eCommerce Websites

Listed below are trendy eCommerce websites:
- Amazon
- eBay
- Walmart
- Alibaba
- Shopify
- Etsy
- Target
- Best Buy
- Flipkart
- Macy's
- Wayfair, etc.
List of Data Fields
The following list of data fields is available from scraping eCommerce websites.
- Product Name
- Description
- Price
- Category
- URL
- Availability
- Reviews
- Ratings
- Specifications
- Seller Details
- Shipping Details
- Discounts and Offers
- Variations
- Brand Name
Significance of Scraping eCommerce Websites
Web scraping plays a crucial role in the success of eCommerce businesses, offering several
key benefits:
- Competitive Intelligence: By scraping competitor websites, eCommerce
businesses can gain valuable insights into their competitors' products, pricing strategies,
promotional activities, and customer reviews. This data helps formulate effective business
strategies, such as pricing optimization, product differentiation, and targeted marketing
campaigns.
- Lead Generation: Scrape eCommerce websites to enable businesses to
discover new leads and potential customers by extracting data from relevant sources like
industry-specific websites, forums, or social media platforms. This information helps
identify prospects, target marketing efforts, and expand customer acquisition.
- Product Research and Sourcing: Web scraping eCommerce websites enables
businesses to efficiently search for new products to sell on their eCommerce websites.
Businesses can gather product information, pricing details, and availability by scraping
supplier websites, online marketplaces, or industry catalogs. It facilitates quick and
informed decision-making regarding product selection and diversification.
- Price Monitoring: With eCommerce data scraping services, eCommerce
businesses can monitor competitors' pricing strategies in real time. By regularly scraping
competitor websites or marketplaces, businesses can stay updated on price fluctuations,
identify competitive pricing opportunities, and adjust their pricing strategies accordingly.
- Content Aggregation: Web scraping helps in aggregating relevant content for
eCommerce websites. It allows businesses to scrape product descriptions, images, customer
reviews, and other information from different sources, saving time and effort while manually
collecting and curating content.
- Inventory Management: Web scraping can assist in monitoring competitors'
inventory levels and product availability. By scraping supplier websites or marketplaces,
businesses can gain insights into stock levels, identify potential supply chain issues, and
optimize inventory management processes.
Though there are n-numbers of eCommerce websites, in this blog, we will take an
example of Amazon eCommerce websites and explain how to scrape data from Amazon eCommerce
websites.
Amazon eCommerce Data Scraping
Amazon, the largest e-commerce corporation in the United States and offering an
extensive range of products, holds a wealth of valuable data. Extracting this data through web
scraping can provide numerous benefits. This guide aims to assist you in developing a practical
approach for extracting product and pricing information from Amazon. You'll learn to efficiently
gather the desired data using Amazon data scraper and techniques.
Benefits of Scraping Amazon Data
Web scraping Amazon data provides valuable insights for competitor price
research, real-time cost monitoring, and identifying seasonal shifts to offer consumers better
product deals. Extracting relevant data from the Amazon website and saving it in a spreadsheet
or JSON format allows you to automate the process and update the data regularly.
Exporting product data from Amazon to a spreadsheet is a complex task. However,
web scraping solves this problem by enabling you to extract the desired data efficiently.
Whether for competitor analysis, comparison shopping, API integration, or other business needs,
you can scrape data from Ecommerce website for several purposes.
Here are some specific benefits of using a web scraper for Amazon:
- Amazon SEO and Marketing: Utilize data from product search results to
enhance your Amazon SEO status and optimize marketing campaigns on the platform.
- Competitor Analysis: Compare and contrast your offerings with those of
competitors to identify gaps, pricing strategies, and opportunities for improvement.
- Review Management and Product Optimization: Leverage review data to
effectively manage reviews and optimize products for retailers or manufacturers.
- Trend and Top-Selling Product Identification: Discover trending products
and access top-selling product lists within specific categories or groups.
Amazon Data Scraping Procedure
For Amazon product data scraping, we will be using Python 3. It's important to
note that the code will not run if you are using Python 2.7. You will need a computer with
Python 3 and PIP installed.
To perform Amazon scraping, you will must install the following Python
packages. You can use the pip3 command to install them:
Requests:
This package allows you to make HTTP requests and download the HTML content of Amazon product
pages. Install it with the following command:
pip3 install requests
SelectorLib:
SelectorLib is a Python package that facilitates data extraction using the YAML file generated
from the downloaded web pages. Install it with the following command:
pip3 install SelectorLib
Use pip3 instead of pip if you are using Python 3.
By installing these packages, you will have the necessary tools to scrape Amazon data
effectively.
Use Selectorlib for Markup data fields.
We will create a new file in the same directory as your code and name it
selectors.yml.
Open the selectors.yml file and define the data fields you want to extract from
the Amazon product pages using YAML syntax. The template should resemble the structure provided
in the file.
Save the selectors.yml file.
The markup preview will appear like this.
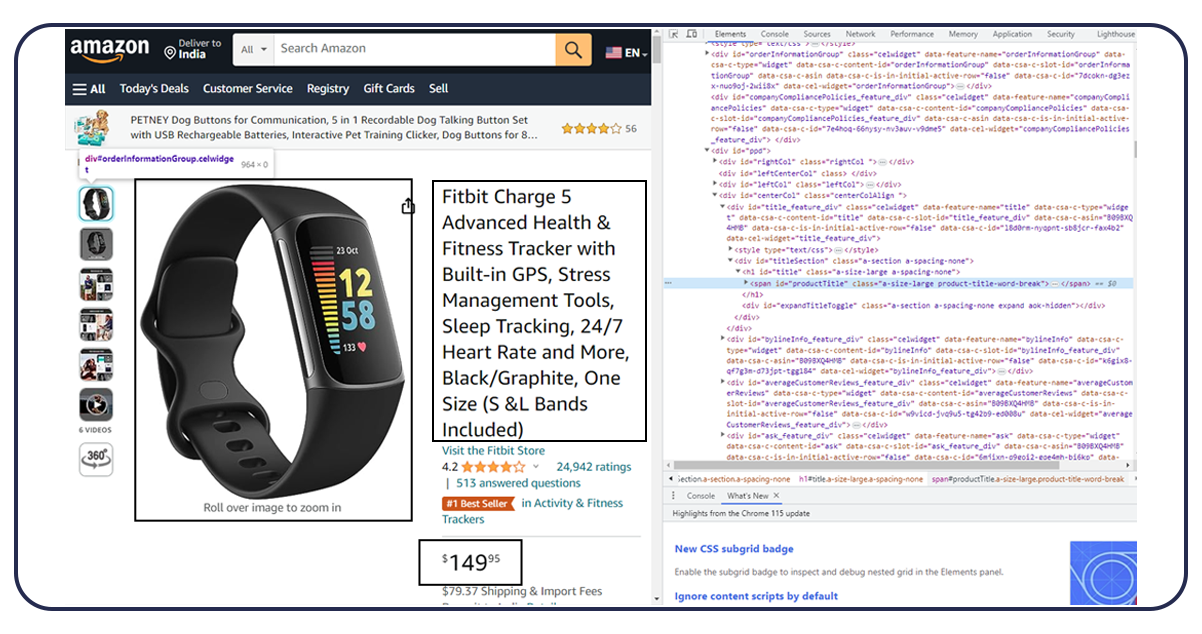
Selectorlib is a developer-friendly tool that simplifies marking up and extracting data from web
pages. It offers a combination of tools that streamline the data extraction process. The
Selectorlib Chrome Extension is one of these tools. It allows you to mark the specific data
elements you want to extract from web pages. By selecting the desired data elements, the
extension automatically generates the corresponding CSS Selectors or XPaths required to extract
that data. Additionally, it provides a preview of how the extracted data will look.
Using the Selectorlib Chrome Extension, developers can quickly identify and mark the data
elements they need for extraction, saving time and effort in manually identifying and writing
CSS Selectors or XPaths. This tool significantly simplifies the data extraction process and
enhances the efficiency of web scraping tasks.
The Code

To implement the scraper for Amazon, follow these steps:
Create a folder named "amazon-scraper" in your desired directory.
Copy and paste the Selectorlib YAML template file, which should be named
"selectors.yml," into the "amazon-scraper" folder.
Create a new file called "amazon.py" inside the "amazon-scraper" folder.
Copy and paste the provided code into the "amazon.py" file. This code performs
the following tasks:
- Reads a list of Amazon product URLs from a file named "urls.txt."
- Scrapes the data from the product pages.
- Saves the extracted data as a JSON Lines file.
Ensure you install the required Python packages, such as Requests and
SelectorLib. Once the code is in place, you can run it to scrape the data from the specified
Amazon URLs and save it in the desired JSON Lines format.

Now, run the product page data scraper by typing the following command:
After the completion, you will see the complete file with the output.jsonl
along with the data.

At Product Data Scrape, we ensure that our Competitor Price Monitoring Services and Mobile
App Data Scraping maintain the highest standards of business ethics and lead all operations. We
have multiple offices around the world to fulfill our customers' requirements.



































.webp)





